Foundations of Web Development

Scott Frees, Ph.D.
Program Director, M.S. Computer Science
Program Director, M.S. Data Science
Program Director, M.S. Applied Mathematics
Convenor, B.S. Computer Science
Convenor, B.S. Cybersecurity
Ramapo College of New Jersey
505 Ramapo Valley Road
Mahwah, NJ 07430
[email protected]
©2025
A foundational guide to modern web development—from protocols to front-end interactivity, grounded in real-world architecture and time-tested pedagogy.
This book isn’t just about HTML, CSS, and JavaScript—though you’ll encounter plenty of all three. It’s a comprehensive guide to the concepts of web development, and how those concepts span across frameworks, languages, and layers of modern full stack applications.
Written for college students, instructors, and professional developers alike, it takes a pedagogically sound, hands-on approach to learning how the web actually works—starting from the ground up. You’ll begin with the fundamentals: internet protocols, TCP/IP, sockets, and HTTP. From there, you’ll build up a working knowledge of web standards like HTML and CSS, and then dive into backend programming using JavaScript in the Node.js runtime—not because it's the only option, but because it minimizes language overhead and maximizes focus on the architecture and ideas that matter.
You won’t learn just one way to build a web app. You’ll build your own framework before adopting industry-standard tools like Express, gaining insight into routing, middleware, templating, databases, and state management. You’ll incrementally evolve a single example—a number guessing game—through nine iterations, each showcasing a deeper or more advanced feature, from form handling to RESTful APIs to reactive front ends built with Vue.js.
You’ll cover:
-
Networks & Protocols – Learn what really happens when you click a link, from TCP handshakes to HTTP requests.
-
Markup & Hypertext – Go beyond tags and learn how HTML works as the structural backbone of the web.
-
JavaScript (Server & Client) – Explore the language in a way that emphasizes conceptual understanding over syntax memorization.
-
Asynchronous Programming – Master callbacks, promises, and async/await as you build responsive, concurrent systems.
-
Databases & State – Learn how modern web apps manage persistent state with relational databases and sessions.
-
Templating & Frameworks – Understand how server-side rendering works from first principles, then leverage Pug and Express.
-
Styling & Layout – Dive deep into CSS, including Flexbox, Grid, and responsive design, before layering in frameworks like Bootstrap.
-
Client-side Development – Manipulate the DOM, handle events, make AJAX requests, and build interactive SPAs with Vue.js.
-
Security, Deployment & Infrastructure – Round out your knowledge with practical insight into authentication, encryption, and modern DevOps topics.
Whether you’re a computer science student getting your first taste of real-world development, an instructor looking for a curriculum-aligned text, or a working developer aiming to fill conceptual gaps, this book will challenge and reward you. It doesn’t shy away from the complexity of the modern web—but it does guide you through it with clarity, consistency, and context.
If you're tired of chasing trends and frameworks without understanding the foundations, this book is your starting point—and your roadmap—for becoming a thoughtful, well-rounded web developer.
Some more of my work...

Professor of Computer Science, Chair of Computer Science and Cybersecurity, Director of MS in Computer Science, Data Science, Applied Mathematics.

My consultancy - Turning ideas into working solutions and real product: building MVPs, modernizing legacy systems and integrating AI and automation into your workflows.

My work on Node.js and C++ Integration, a blog and e-book. Native addons, asynchronous processing, high performance cross-platform deployment.
Introduction
What, Who, Why
This book is not a comprehensive reference for any programming language - although you will see quite a lot of HTML, CSS, and JavaScript. This book is a comprehensive guide to web development concepts - including server side (backend) and client side (front end) development, and most things in between. We will keep our attention on the design of the web architecture, concepts that remain constant across so many of the programming languages, frameworks, and acronyms you’ve probably heard about. This book won’t play favorites - you’ll see how different architectural styles like Single Page Applications (SPA) differs from Server Side Rendering (SSR), how Representational State Transfer (REST) using JSON differs from Hypertext as the engine of application state (HATEOAS), and how conventional “roll your own” CSS can blend with full styling frameworks. This book covers the full stack.
If you are a beginner in computer science and programming, you are in for a ride - a fun one! We won’t assume you know advanced programming concepts, but we will move quickly - you will be challenged if you haven’t done much software development. One promise I can make is that you won’t walk away with shallow knowledge - we will cover concepts from the ground up, which will allow you to pick up new trends in web development as they arise - well after you are done reading this book. You won’t be taught one way of doing things, only to be left feeling lost when the next web framework becomes the new hotness of the world.
For seasoned developers new to web development, you might be surprised to learn web development doesn’t have to be the fad-obsessed, inefficient "Wild West" it can sometimes appear to be. The essentials of web development can be grounded in solid software engineering, and can be simple - if not always easy.
This book is written for university students and professionals alike. If you’ve already done some work in web development, you will likely still learn a lot from seeing things presented from a foundational perspective. Once you’ve mastered the concepts presented here, you will be better able to make use of new development trends, and make better connections between the acronym soup you encounter as you dive deeper into the discipline.
Languages and Organization
The web is programming language agnostic. The web runs on open protocols - mostly plain text being transmitted back and forth between web browsers (and other clients) and web servers. Clients and servers can programmatically generate their requests and responses using any language they want - as long as the text they are producing conforms to web standards.
You might be surprised, or even a little confused by this - especially if you've only just started studying Computer Science and the web. You've heard of HTML, CSS, JavaScript, and probably also heard people talking about Java, C#/ASP.NET, Python, Go, Rust, and a whole slew of other languages when they talk about web development. It can be absolutely befuddling... where do you start? If there isn't just one language, then which should you learn?
The other hard part about getting started with web development is that it's really hard to draw boundaries around it. Does web development include working with a database? Does it include UI design? How about distributed computing? What about queues? The answer is... yes - it probably includes everything! The reality is that a web application is a system - and depending on what it does, it could contain functionality associated with just about every branch of computer science. A typical web developer has to (or should be prepared to) integrate a lot of different sub-disciplines. In fact, the bulk of the complexity in many web applications have nothing to do with web development at all!.
In this book, we are going to try really hard to stick to purely web development, but not to the extent that you won't understand the integration points to things like UI design, databases, networks, etc.
I strongly believe there shouldn't be a distinction between web developer and software developer, and this book is written for reader who agree.
JavaScript, everywhere?
 This book uses JavaScript as a server side language, running within the Node.js runtime environment. This choice is somewhat controversial - since there are wonderful frameworks and support for many programming languages on the backend. No question, the use of .NET ASP MVC, Python, Java, Rust, Ruby on Rails, Go and many others could be more than justified. The truth is that you can find just about any programming language being used professionally on the backend - and many applications use a mix of languages!
This book uses JavaScript as a server side language, running within the Node.js runtime environment. This choice is somewhat controversial - since there are wonderful frameworks and support for many programming languages on the backend. No question, the use of .NET ASP MVC, Python, Java, Rust, Ruby on Rails, Go and many others could be more than justified. The truth is that you can find just about any programming language being used professionally on the backend - and many applications use a mix of languages!
I have chosen JavaScript for no reason other than this: If you are new to web development, you must learn JavaScript for client-side browser-based development. Learning multiple programming languages at the same time obscures concepts - and concepts are what this book is about. In teaching web development to undergraduate university students for over a dozen years, I’ve found that using JavaScript limits the overhead in learning web topics. If you already know the JavaScript language, this book will give you a tour-de-force in web development concepts - without needing to learn a new language. If you are new to JavaScript, this book should give you enough of a primer while teaching you the backend such that by the time we cover client side programming, you’ll be able to focus on concepts and not syntax. Once you learn the concepts of web development, you won’t have trouble moving to other languages on the backend if you prefer.
There are other arguments made for JavaScript on the backend, such as sharing code between server and front end runtimes, and the suitability of JavaScript’s I/O model for backend web development. These arguments have some validity, but they aren’t universally agreed to by any stretch. We use JavaScript here for no other reason but to flatten the learning curve.
On the front end, there are of course other paradigms beyond JavaScript. There is no question that JavaScript has some rough edges, and until very recently lacked many language features that support solid application development. Still at the time of this writing (and well beyond I imagine!), JavaScript is not a strongly typed or compiled language - and those attributes alone rub some the wrong way. TypeScript is a widely popular derivation of JavaScript, adding many features such as strong typing and better tooling to JavaScript. Like many of it's descendent (or inspirations), such as CoffeeScript, TypeScript compiles to plain old JavaScript, so it can be effectively used to write both backend and front end applications.
WebAssembly continues to grow in popularity and promise, allowing developers to run many different languages within the browser. At the time of writing, WebAssembly supports executing C/C++, Rust, Java, Go, and several other performant languages directly within the browser - bringing near native performance to front end code. The caveat, for the time being, is that WebAssembly code executes this code in a sandboxed environment that does not have access to the browser's document object model (DOM) - meaning interacting seamlessly with the rendered HTML is not yet achievable.
This book will only touch on the above alternatives for front end development, sticking with plain old JavaScript instead. Once again, this decision is rooted in the learning curve. The aim of the book is to teach you how web development works, and whether you are writing JavaScript, TypeScript, or WASM-enabled C++/Java/Rust/etc - front end development is still front end development - so we are going to stick with the most straightforward choice - JavaScript here.
Organization
This book teaches web development almost in the order in which things developed - first focusing on networks, hypertext, markup and server side rendering. You will be introduced to JavaScript early on when, just before we begin processing input from users. We will build our own frameworks around HTML templating, databases, routing, and other common backend tasks - only to have our homegrown implementations replaced with Express. The Express framework was chosen for its relative stability and ubiquity, among the many frameworks in use within the Node.js ecosystem.
Only after we have a full web application up and running do we begin to turn our attention towards styling and interactivity. CSS is introduced approximately midway through the text book, and client side JavaScript makes up the majority of the final half dozen chapters. This book will show you the differences between traditional web applications, single page applications, and cover hybrid approaches that adhere to Hypertext as the engine of application state (HATEOAS) philosophy, while still providing interactive (and incrementally/partially rendered) user interfaces. Along the way, we will cover things like local storage, PWAs, web sockets, and reactivity.
The Appendices and Perspectives sections at the end of the text are optional components aimed towards filling in some of the details different readers may be wondering about. The goal of the entire textbook, in fact, is to do this that - fill in the gaps - by providing a comprehensive overview of web development.
The Field of Web Development
Web applications are just software applications, with networking.
Maybe more specifically, they are software applications with networking separating the user interface (the part people see and click on) and the business logic. No matter what languages you use, the general design of the frameworks you will find are pretty much the same. The industry is very cyclical, and very susceptible to buzzwords and trends. For example, I've witnessed several iterations away and back to server-side rendering. I've witnessed front end development changing to require it's own application and build structure, separate from the rest of the application; and I've witnessed a revolt against this taking hold - perhaps returning us to simpler architectures.
For a long time, web development was thought of as a lesser sub-field of computer science. Real programmers built "big" programs that had their own UI's and were written in C++ and Java. Toy web sites had some JavaScript, and were written in "broken" scripting languages like Perl and php. Real programmers couldn't be bothered with creating applications for the web, and even if they wanted to, web browsers were such a mess that it was too expensive and error prone to pull off. Times have changed, and few think of web development as lesser anymore. It's been a fascinating ride.
The change started to take hold in the early 2000's. While it took a long time, the dominance of Internet Explorer waned, and the competition among browsers fostered improving web standards. Better standards meant web developers had a better chance to make their app work well on everyone's machines. Browsers like Chrome also got way faster, and way more powerful - making it worth everyone's time to start looking at what they could do with JavaScript. Suddenly, real application were starting to be delivered on web technology - driving more development focus into those same technologies. HTML got better. CSS got a lot better. JavaScript grew up.
Along the same time as all these nice things were happening on the front end, back end (server-side) development was changing too. The first web application were written in a way most wouldn't recognize - actually instantiating new processes and running entire programs to respond to each request. These programs could be written in any language, and a web server would handle the networking and invoke the appropriate (compiled) program to create the network response. Languages like php and ASP, and later Java extended this model, allowing server side applications to be written as one process in it's own containers. These containers handled a lot of the web-specific plumbing, like making parsing / writing HTTP much easier. They all focused on different ways of allowing developers to generate HTML responses programmatically, and they all took somewhat different approaches. There was little separation of concerns - the business logic, HTTP processing, HTML generation, and other aspects of the programs were highly integrated. Applications written in different frameworks looked completely different from each other, even if they largely did the same thing.
Ruby on Rails - or just "Rails" - was released in 2004, and things changed. Rails took a number of huge leaps in how server side frameworks worked. Rails pioneered and/or refined rapid application development on the server, using command line interfaces to build out routes, controllers, and views. Web applications began to be more modular, and composable. It worked with view template engines to separate view generation from business logic. It didn't invent the MVC pattern, but it was really the first web framework to truly deliver on the MVC promise. We'll talk a lot more about it later in this book.
By the late 00's, and throughout the 2010's, both of the above trends just strengthened. Web standards and browser performance led to more developers doing more things client side, in JavaScript. As this happened, developers wanted better tooling, better dependency management, better UI frameworks - so they built them. Server side, developers loved how Rails was designed, but they wanted to use their favorite programming language - not just Ruby. Server-side frameworks heavily influenced by Rails emerged - Django (Python), Laravel (PHP), Grails (Groovy/Java), Express (Node.JS), and many more. Even .NET was on board - releasing ASP.NET MVC - very much in line with the Rails design.
Modern web development has benefited by a virtuous circle - as tools and languages and standards improved, the amount being done on the web grew, which demanded even better tools, languages, and standards. The explosion of different devices accessible to people also created huge demand for standards. Today, nearly every software application we interact with - whether it's through a traditional web browser or through an app on our phone - is a web application. In many respect, today, web development is software development.
The landscape
We are eventually going to focus on a slice of web technologies (our "stack"), but it's important to have an understanding of how things fit together. We've been throwing around some terms that need explanation:
Front end
Front end development refers to all the code used to display the user interface to a user - wherever that user interface might live. In most cases (in the context of this book), this is the web browser. The web browser must draw the user interface (the graphics, the user interface elements, etc.) using code delivered to it from the web server. The code delivered tells it the structure of the web page, the styles of the page, and the interactivity of the user interface.
On the front end, we generally have three languages for these three aspects:
- Structure: HyperText Markup Language (HTML)
- Style: Cascading Style Sheets (CSS)
- Interactivity: JavaScript
Let's look at a tiny example, a simple web page that has a bit of text, and a button.
<!DOCTYPE html>
<html>
<head>
<title>Tiny Example</title>
</head>
<body>
<h1>Let's get started!</h1>
<p>This is an example of a <span>very, very</span> minimal web page.<p>
<p>
<button type='button'>Click me</button>
</p>
</body>
</html>
Without getting stuck on any details, understand that the above is HTML code. It is defining a page with a heading, some text, and a button. It's the structure of the page. We'll spend lots of time talking about HTML later.
How does this get displayed to a user? The answer is important, and be careful to understand it. The HTML, as text, must be loaded into a web browser, somehow. If you take the text, and you save it in a file called example.html on your computer, you can load it in your web browser by simply double clicking on it. It will look something like this:
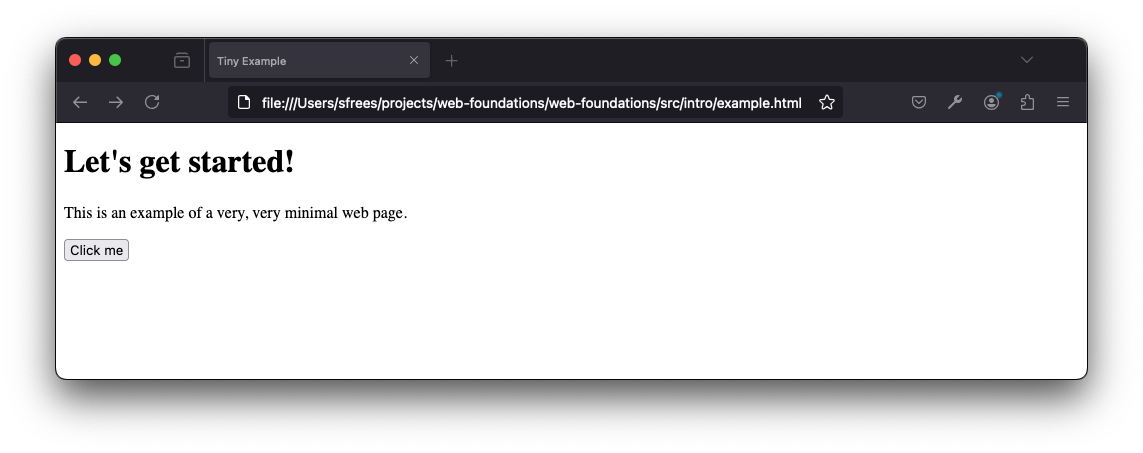
Notice what is shown in the URL address bar.
file:///Users/sfrees/projects/web-foundations/web-foundations/src/intro/example.html
The browser has loaded an HTML file directly from the file system and displayed it. To display it, it parsed the HTML into it's own internal representation and invoked it's own drawing/graphics commands to render the page according to HTML specifications.
While that's OK, you must understand that this is not the way the web works. HTML files that appear in your web browser are not stored on your own computer in most cases. In most cases, they are stored on some other machine, on the internet!
This brings us to our first shift away from "front end", and to the back end (and the networking in between). We are going to refine our understanding of this over and over again, here we are going to keep things very high level.
Back end
Type the following into your web browser's address bar:
https://webfoundationsbook.com/wfbook/intro/example.html
The same page loads, but this time, that file didn't come from your own computer. Delete example.html from your own machine, if you don't believe me. Instead, it came from a different machine - webfoundationsbook.com. When you typed the address into your web browser, the web browser connected to webfoundationsbook.com, it sent a specially crafted message (as you'll see soon, crafted with HTTP) asking webfoundationsbook.com to send the text contained in a file found at /intro/example.html on webfoundationsbook.com's hard drive. That text was then parsed and rendered by the browser, just the same.
In order for that to all work, that means some program must be running on the webfoundationsbook.com computer. That program is accepting connections and requests from other machines. It's decoding the requests, finding the file requested, opening the file, and sending the contents of the file back to the connected browser! That program is a web server.
Some of the most common web servers for doing this (and much more) are apache or nginx. We will see more of those later on in this book.
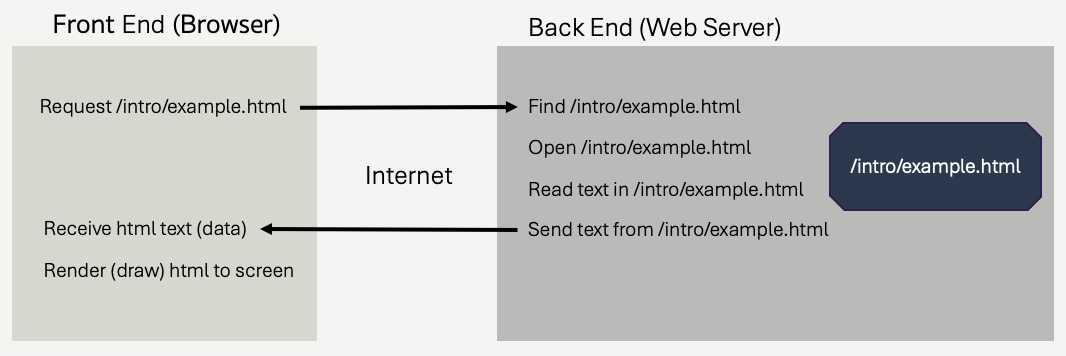
The browser's pseudocode, vastly simplified, might look something like this.
// Pseudocode for the web browser
// Suppose we can access the values in the UI through
// through a built-in browser object
response = send_http_request(browser.address_bar.value);
// The response object might have a body attribute, containing
// the HTML text that was returned by the server.
render(response.body);
Here's some pseudocode (missing vital error handling!) further illustrating what is happening on the server.
// Pseudocode for a web server
// Suppose we have function to read a request off
// the network, from a browser
request = recv_http_request();
// Suppose the request object returned has a path
// property, corresponding to /intro/example.html
// when the browser requests https://webfoundationsbook.com/intro/example.html
file = open_file(request.path);
// Read the html from the file, as plain text (character buffer)
html_text = file.readAll();
// Use a function to send the data back to the browser
send_http_response(html_text);
So, already, we see there are typically two programs involved - (1) a web browser and (2) a web server. The web browser asks for and receives front end code from the server - in this case html. The web server is responsible for generating that text - in this case, simply by reading the example.html file from it's own file system. Once the web browser receives the HTML code, it uses it to draw the page to the screen.
If you are wondering, web browsers and web servers can be written in literally any programming language. Most web browsers are written in C/C++, and some have at least some components written in other languages like Rust. Web servers, especially the top level ones (we'll explain what that means later) are also often written in C/C++. It's important to remember, they are just ordinary programs, they read files, they make network connections (sockets), they parse and generate specially formatted text, they draw things (browsers, not servers).
Return to the front end - Styling
So we've established that HTML code is delivered to a web browser, usually from a web server. That HTML code defines the structure of the page. Web browsers use standard conventions to draw HTML to the screen in expected ways. Looking at the HTML we were using, notice the text that is wrapped in the <h1> and <button> elements. They look different than the other bits of text wrapped in <p> and <span>. h1 is a heading, button is pretty obviously telling the browser to draw a button. p is a paragraph and span is a text span within a paragraph that can be styled differently (but isn't yet). This is the structure of the page - it's contents.
Front end code also is used to define style and interactivity. Let's add just a bit of style, by making the heading's text underlined, and the span's text blue. We do this by adding Cascading Style Sheet (CSS) rules. CSS is a language unto itself, and we will study it in several future chapters - but for now, we will just embed it right into our HTML code.
<!DOCTYPE html>
<html>
<head>
<title>Tiny Example</title>
<style>
h1 {
text-decoration:underline;
}
span {
color:blue;
}
</style>
</head>
<body>
<h1>Let's get started!</h1>
<p>This is an example of a <span>very, very</span> minimal web page.<p>
<p>
<button type='button'>Click me</button>
</p>
</body>
</html>
All the magic is happening within the style element - we've used CSS syntax to tell the browser to style h1 elements and span elements a bit differently. Go ahead and load the following in your web browser, no surprises - just some styling.
https://webfoundationsbook.com/intro/example-style.html
CSS can be used to define all aspects of the visual styling and layout of HTML content. It's an immensly powerful language, that has undergone incredible cycles of improvements over the decades since it's introduction. While there were some early competitors, no other language is used to style HTML these days - CSS is the language. All browsers support CSS (at least, mostly).
Since visual styling is so important, it shouldn't be surprising that CSS styling code can grow - it can become a huge part of the front end development efforts. If you have any experience in computer science and software engineering, you know that we like to reuse code. CSS is no different - reusing and modularizing CSS is important when creating maintainable web applications. Moreover, not all of us are artists - we aren't all trained in good UI practices. It shouldn't be surprising that there are libraries and frameworks that contain vast quantities of CSS code designed by people who are really good at designing visual systems, and that these libraries and frameworks are often freely available.
Here are a few example of CSS libraries and frameworks that are commonly used. The list isn't exhaustive, but hopefully it gives you an idea of how they fit into the web application landscape if you've heard about them. They are just CSS, they are added into your HTML to provide the web browser styling instructions.
- Bootstrap - likely the most widely used framework, this has been around for a long time. Provides full styling of everything from text, navigation toolbars, dialogs, and more. We will spend some time looking at this in more detail in later chapters.
- Foundation - similar in aims to bootstrap, Foundation provides full styling of most user interface components.
- Tailwinds - takes a different approach compared to Bootstrap and Foundation, in that it focuses on composable CSS styles rather than full user interface components. This gives designers more control, but can also be harder to get started with.
- Simple.css - lightweight CSS framework that provides an extremely minimal set of stylings for HTML elements. Theses types of frameworks are really nice for rapid development, because they don't require you to add much to your HTML at all. Their goal is to get things looking "good" immediately, and then you can add more later.
There are also more specialized libraries defining styling. By more, I mean thousands. They are all just CSS, that get added to your front end HTML code. Here are some two interesting ones, just to show how varied they can be.
- United States Web Design System - this is the standard CSS frameworks for use on United States government web sites. Many other countries have similar frameworks. The goal is to provide extremely high quality out-of-the-box accessibility.
- NES.css - all the way on the other side of the spectrum, here's a CSS library that simply styles all your HTML so the page looks like it's from the Nintendo Entertainment System from the 1980's. It's fun, but certainly not general purpose!
Front end interactivity
The page we've been looking at is static. Once it's shown on the screen, it doesn't change. The HTML and CSS are delivered to the browser, and that's that. What if we want something to happen when we click that <button> element though? This is where we can add some interactivity. Interactivity on the web generally means creating code that alters the HTML or CSS currently loaded in the web browser, causing something to change. It can mean more, but for now that's a good enough description.
Let's add some interactivity. When the user clicks the button, we are going to add some content below the button and change some of the CSS attached to the span element.
<!DOCTYPE html>
<html>
<head>
<title>Tiny Example</title>
<style>
h1 {
text-decoration:underline;
}
span {
color:blue;
}
</style>
</head>
<body>
<h1>Let's get started!</h1>
<p>This is an example of a <span>very, very</span> minimal web page.<p>
<p>
<button type='button'>Click me</button>
</p>
<script>
// Change the "very, very" to red, and add a new text snippet
// with a random number, and remove the button so it can't be clicked
// again!
document.querySelector('button').addEventListener('click', () => {
document.querySelector('span').style.color = 'red';
const n = Math.ceil(Math.random() * 10);
const p = `<p>Random number generated client side: ${n}`;
document.querySelector('p').innerHTML += p;
document.querySelector('button').remove();
});
</script>
</body>
</html>
Go ahead and check it out. When you click the button, something really important is happening - the JavaScript inside the script element is changing the HTML itself, using what is called the Document Object Model (DOM). The span is given a new CSS value for color. A new p element is created and appended to the last p element in the document, with a random number within the text (it's different every time you load the page). The button is removed entirely. Notice, the browser changes what is rendered as the JavaScript changes the DOM elements. The DOM elements are what the browser renders - they are the internal representation of the HTML loaded by the browser.
It's important to understand that the JavaScript code that modified the HTML DOM is running inside the web browser. The web browser, in addition to a renderer, a JavaScript runtime environment! The server is not involved in anything that we just did, it has no idea anyone has click a button, or that any HTML has been modified. It all happened within the browser's internal representation of the HTML the server sent to it.
Interactivity on the front end, using JavaScript could (and most definitely is) be the subject of entire books, entire courses, and entire careers. As you might imagine, there are a huge number of frameworks that help developers write JavaScript to add an enormous amount of interactivity to HTML. You've no doubt heard of some.
- jQuery - probably the first and most broadly used JavaScript framework, in many ways it revolutionized how we wrote JavaScript. jQuery was created in 2006, when JavaScript suffered from a very poorly standardized DOM API, meaning writing JavaScript to interact with the HTML DOM (change things on the page) needed to be written differently depending on the browser. THis was also a time when Internet Explorer was still quite popular, but Chrome, Safari, and Firefox were too large to be ignored. jQuery created a very powerful API that smoothed over the differences. It inspired iterations to JavaScript itself, which later became part of the standard web APIs across all browsers. jQuery isn't often used these days, because JavaScript has evolved enough that it's no longer necessary - but it's impact is still felt.
- React - released in 2013, React became the most popular reactive framework/library very quickly, and has remained so through the time of this writing. React focuses on component design, and has offshoots like Reach Native which aid in mobile application development. The concept of reactivity centers around how developers map application state (usually state is represented by JavaScript objects) to HTML DOM changes. Reactive frameworks allow the developer to modify state variables, and those changes are automatically applied to the DOM based on declarative rules. This is very different than the procedural approach in our JS example above, where we directly modify the DOM. There are many reactive frameworks, the concept is extremely powerful.
- Vue - released in 2014, Vue is similar to React in terms of it's model of development. A proper Vue app manages front end application state, and automatically modifies the DOM based on those state changes. It has what many people feel is a shallower learning curve than React, and we will use it when we dive deeper into reactive frameworks and single page application design later in this book.
- Angular - AngularJS was initially released in 2010, and rewritten (and renamed to Angular) in 2016. Angular shares a lot of design principles with React and Vue, along with other predecessors like Ember and Knockout.
There are lots and lots of other front end JavaScript libraries and frameworks. Some are large, some are very small. While we won't dive too deeply into them, we will learn the fundamentals of JavaScript on the client (front end) in depth, and you'll be able to pick many of these frameworks up pretty quickly once you've mastered the basics.
Back to the Back end
We could have a web site just with HTML, CSS, and JavaScript. You could have lots of HTML pages, link them together, and use CSS and JavaScript to do a lot interesting things.
We could write our own HTML, CSS, and JavaScript in a text editor, and use a SFTP program to transfer those files to a simple web server that can map network requests from clients to these files. Those files are then transmitted to the browser for rendering. This is in fact still very viable, it's probably still how most web pages are delivered.
However, there is something missing. Our pages are still static in that they are always exactly the same, whenever they are loaded into the browser. Sure, our front end JavaScript might change the DOM later, but it's always exactly the same HTML, CSS, and JavaScript being delivered to the browser, because we are just serving up files.
As a little thought experiment, what if we rewrote the server pseudocode from above so we didn't use a file at all?
// Pseudocode for a web server, without a file.
// Suppose we have function to read a request off
// the network, from a browser
request = recv_http_request();
if (request.path == '/intro/example.html') {
html_text = "<!DOCTYPE html><html><head><title>Tiny Example</title></head>";
html_text += "<body><h1>Let's get started!</h1><p>This is an example of a ";
html_text += "<span>very, very</span> minimal web page.<p><p>";
html_text += "<button type='button'>Click me</button></p></body></html>";
send_http_response(html_text);
}
else {
// send some sort of error, we don't have anything for this path...
}
If you look closely, the web server is sending exactly the same text to the web browser when the browser requests /intro/example.html as it was before. The difference is that instead of getting the HTML text from a file saved on disk, the web server is just generating the HTML using string concatenation. It's ugly, but it works - and in fact, the browser cannot tell the difference.
Why would we do this? The answer is simple, and profoundly important. Now, since we are generating the HTML inside a program, we have the freedom to create different HTML whenever we want. We can fetch data from a database, and include that data in the HTML. We can perform any number of computations, interact with any number of data stores and systems, and use any other mechanism to customize the HTML delivered to the browser. We now have the ability to create a fully customized HTML response to /intro/example.html if we please.
To drive this point home a little more, let's generate a random number and put it in the HTML sent to the browser.
// Pseudocode for a web server, without a file.
// Suppose we have function to read a request off
// the network, from a browser
request = recv_http_request();
if (request.path == '/intro/example.html') {
html_text = "<!DOCTYPE html><html><head><title>Tiny Example</title></head>";
html_text += "<body><h1>Let's get started!</h1><p>This is an example of a ";
html_text += "<span>very, very</span> minimal web page.<p><p>";
html_text += "<button type='button'>Click me</button></p></body></html>";
send_http_response(html_text);
}
else if (request.path == '/intro/example-style-js.html') {
number = Math.ceil(Math.random() * 100);
// The beginning is just static text content
html_text = "<!DOCTYPE html>";
html_text = "<html>";
html_text = " <head>";
html_text = " <title>Tiny Example</title>";
html_text = " <style>";
html_text = " h1 {";
html_text = " text-decoration:underline;";
html_text = " }";
html_text = " span {";
html_text = " color:blue;";
html_text = " }";
html_text = " </style>";
html_text = " </head>";
html_text = " <body>";
html_text = " <h1>Let's get started!</h1>";
html_text = " <p>This is an example of a <span>very, very</span> minimal web page.<p>";
// Here's the dynamic bit, with the server generated number in the text.
html_text = " <p>The server generated number is: " + number + " </p>"
// The rest is static again.
html_text = " <p>";
html_text = " <button type='button'>Click me</button>";
html_text = " </p>";
html_text = " <script>";
html_text = " document.querySelector('button').addEventListener('click', () => {";
html_text = " document.querySelector('span').style.color = 'red';";
html_text = " const n = Math.ceil(Math.random() * 10);";
html_text = " const p = `<p>Random number generated client side: ${n}`;";
html_text = " document.querySelector('p').innerHTML += p;";
html_text = " document.querySelector('button').remove();";
html_text = " });";
html_text = " </script>";
html_text = " </body>";
html_text = "</html>";
}
else {
// send some sort of error, we don't have anything for this path...
}
Right about now, you may be getting a sick feeling in your stomach. We are writing code, inside code. Worse yet, we are writing code (a mix of HTML, CSS, and JavaScript) inside plain old strings, and using concatenation to build it all up. This is a tiny example. If you feel like this won't scale well up to real web applications, you are 100% correct!
Now we've arrived at the land of back end frameworks. Server side, backend web frameworks handle the following types of things (and many more):
-
HTTP parsing / formation - we side stepped this by imagining we had functions like
recv_http_requestandsend_http_response. In reality, these types of functions will be part of a web server framework/library, and will be doing a ton of work for us. -
Path routing - we have the beginning of routing in our last example, where we use
ifandelse ifstatements to determine which response to generate based on the requested path. Routing is a major part of web development - the server needs to respond to many many different paths (urls). Web frameworks will provide methods of organizing your code into functions, objects, and modules that map to specific paths/urls, and the framework will ensure the right handlers are called at the right time. -
View transformations - we aren't going to generate HTML with strings. We are going to build objects of data programmatically (models), and then use templating engines to transform the data into HTML (views)using a template language. It's a mouthful, but when we get there, you will see how much easier it makes things! There are tons of templating languages, and most do pretty much the same thing. If you've heard about ejs, Jinja, pug, HAML, Liquid, Mustache, or Handlebars... they are all templating languages with large following in the web development community. We'll talk about pug in more detail later. Once you learn one, the others are very easy to pick up.
Full featured web frameworks tend to cover #1 and #2, and typically will let you choose which templating language (#3) to use. Modern frameworks are available in just about every programming language you can think of. Most modern frameworks support the Model-View-Controller (MVC) Architecture - which we discussed a bit above. MVC is a way of organizing the application in a way that separates model (the data), the view (HTML generation), and the business logic (also called controller).
It's hard to say if one is better than the other - there tends to be a few good choices for each programming language. Which programming language you choose is probably more of a decision based on you and your teams skills, and preferences - rather than anything specific to the web.
Here's a sampling of some popular backend web frameworks. Each of these covers all of the above, and often includes more. Note that your choice of a backend framework has nothing to do with anything we've discussed about the front end. They are completely separate!
- Python
- Java (and JVM languages)
- Rust
- Ruby
- PHP
- C++
- .NET
- JavaScript (Node.js)
We'll discuss frameworks in depth later in the book.
Pro Tip💡 You don't want to describe yourself as "a Django developer" or "Laravel developer". You want to learn backend web development and be comfortable in any language or framework. You want to call yourself a web backend developer - or better yet - web developer. Specialization is marketable, and valuable, but you never want to pigeonhole yourself into one framework - it advertises a lack of breadth.
In-between and outside
We've glossed over the in between part, the technology that connects the front end and back end. That's networking, and that is HTTP. We will cover that extensively in the next few chapters!
Outside the typical discussion of front end and back end development are all the systems components and concerns that tend to make up web applications of any complexity. This includes security, understanding TLS/HTTPS, hashing, authentication, CORS, and more. This includes databases of all kinds - relational, document stores, and more. We'll also need to learn about hosting, content delivery, and deployment. It's a lot of ground to cover, and there are chapters dedicated to these topics later in the book.
Breadth & Depth
The goal of this book is to give you enough breadth to understand how all of the pieces of web development fit together. You'll understand the fundamentals in a way that allows you to pick up new frameworks quickly. You will understand the entirety of full stack web development.
The second goal of this book is to give you depth along a particular set of frameworks/libraries so you can build a full scale web app from the ground up. You will understand how front end and backend frameworks work at a low level, and then see how we apply layer after layer until we reach modern framework functionality. We'll choose specific frameworks at each step - for bot the front end and back end - and get a lot of experience using them.
About the Author
I'm Scott Frees - the author. I've been teaching Computer Science at Ramapo College of New Jersey since 2006. I am currently a Professor of Computer Science, and the Director of the Master's in Computer Science, Applied Mathematics and Data Science degrees at Ramapo. I am also the chair of our Computer Science and Cybersecurity departments.
I completed my PhD at Lehigh University in 2006, where I developed new ways for interacting within immersive virtual environments. Virtual Reality has come a very long way since I was doing this work (that's me below).

While completing my PhD, and ever since, I have been an active consultant and freelance developer. It's a passion of mine, because what I really like about computer science is building things people actually use. I've always liked user interface design, but I've also been drawn to building systems - the backend of a software application. Freelance development has given me the opportunity to do all this, in a lot of different domains. I've created software to design oil and gas industrial equipment, track and detect aircraft using 3D cameras, and analyze genomes. I've gotten to develop computer vision-enabled security camera systems, IoT network protocols, mobile apps to manage construction sites, finance/trading platforms, and a bunch of other smaller (and just as fun) projects. Every one of those (except the aircraft detection...) has been a web application at it's fundamental core - but they've all contained a boatload of complexity outside of what is typically considered web development. This is why I think it's so important that every software developer learn web development - it broadens your impact, and it doesn't take away from developing large systems.
I've tried to combine my passion for building things with my love of teaching. In 2015 I created a blog and later an ebook that covered a professional niche topic that I had been doing a lot of work in - Node.js C++ integration. For anyone looking to get into freelance software development - my best advice is do something like this. It's called content marketing, and it's led to lots of opportunities for me. The time I put into writing the book has been repaid many times over from the projects that grew out of help I was providing readers.
I created the Web Development course at Ramapo College in 2007. My experience at that point was mainly in the Java world. The Java web development world in the early 2000's wasn't a wonderful place - web development was hard, and it was without a lot of best practices. The course evolved with me, over almost two decades. The course adopted jQuery for a while, and dabbled with ASP.NET (mainly because we had a C# course that our students already took, making .NET attractive). By 2014, the course had shifted to Node.js as the backend language with Express as the framework of choice. The course design was innovative at the time, fully leveraging the Node.js ecosystem and the MEAN stack to teach undergraduates. Since then, I've stopped covering the M in the MEAN stack (MongoDB), as the industry (and me) have circled back to the tried and true relational database for most use cases. The A in MEAN has also gone away - I don't teach Angular anymore (or jQuery). Modern front end JavaScript is vastly superior to what it was when I started, and most of what we cover in class is now just straight up JavaScript - although I still cover modern reactive frameworks to some extend (i.e. Vue).
If you are a software developer who likes to have people use your work, then you should consider becoming a web developer ;) Targeting the web lets you deliver your work to everyone, directly. It's an amazing experience to have people really use your work - and my hope is that this book can be a helpful tool for you along the way to reaching that goal.
Some more of my work...

Professor of Computer Science, Chair of Computer Science and Cybersecurity, Director of MS in Computer Science, Data Science, Applied Mathematics.

My consultancy - Turning ideas into working solutions and real product: building MVPs, modernizing legacy systems and integrating AI and automation into your workflows.

My work on Node.js and C++ Integration, a blog and e-book. Native addons, asynchronous processing, high performance cross-platform deployment.
Networks

As a web developer, you typically work far above the level of Internet Protocol (IP), Transmission Control Protocol (TCP), sockets and the other underpinnings of computer networks and the internet. Typically is not the same as always, however. Moreover, having a solid understanding of how the web technologies have been built on the back of core technologies like IP/TCP gives you a huge advantage when keeping up with the ever changing field you are entering.
This chapter provides you the fundamental knowledge and skills needed, and also the perspective to not only understand the modern web and it’s tooling, but also appreciate it. Having a solid understanding of networking concepts will also come to your rescue when learning about deploying your web applications along with other devop type activities.
Network Protocols
When we say the web, it's fair to think about web browsers, web sites, urls, etc. Of course, the term "the web" is commonly used interchangeably with the internet. Truly, the internet is a lot more broad than you might realize though. The internet is a global network of computers. It facilitates your web browser accessing a web site. It facilitates email delivery. It lets your Ring security camera notify your phone when the Amazon delivery arrives. When we talk about the internet we are talking about the entire internet - which encompasses billions (if not trillions!) of devices talking to each other.
The first thing we need to understand about computer networks is the concept of a protocol. A network is just a collection of devices, sending electrical signals to each other over some medium. In order for this to be useful, we need some things:
- We need to know how to find devices to talk to
- We need to know how to translate electrical signals into useful information
There's a whole bunch of things that flow from those two requirements. It might help to first consider some real world protocols. The postal system comes to mind.
When we want to mail a physical thing to someone, what do we do? First, we need to know their address. We need to know that (at least in the United States) that addresses look something like this:
98 Hall Dr.
Appleton, WI 54911
There are rules here. On the second line, we expect the town or city. The abbreviation after the comma needs to correspond to an actual state in the US. The number after the state is a zip code, or postal code. This indicates not only a geographic area, but also a specific post office (or set of post offices) that can handle the mail going to addresses within that postal code.
Here we have the beginnings of point #1 above. There is an expectation of how an address is defined and interpreted. It's an agreement. If you think more carefully, there are more - such as where you write this address on an envelope, etc. All of the things associated with filling out an address on an envelope is part of the mail system's protocol.
We also know that our mail can enter the mail network through various places - our own mailbox, or a public postal box. From that point, there is a vast infrastructure which routes our physical mail to the appropriate destination - taking many hops along the way, through regional distribution centers, via airplane, train, truck, to the local postal office, and then to the physical address of the recipient. We intuitively know that this requires a lot of coordination - meaning all of the various touch points need to know the rules. They need to know where to route the mail!
With #1 out of the way, how does the mail system handle #2 - exchanging meaningful information? Interestingly enough, the postal system actually does very little to facilitate this. Just about the only thing it ensures (or at least attempts to) is that when you mail something to someone, they will receive the whole thing, in reasonable condition. If I mail a letter to you, the postal system's promise to me is that the entire letter will arrive, and it will still be readable.
So, how do we effectively communicate via the postal system? Well, the postal system is one protocol - for mail transport and delivery - but there is also another protocol at work. When you send a letter to someone in the mail, you implicitly make a few assumptions. Most importantly, you assume the recipient speaks (or reads) the same language as you, or at least the same language the letter was written in. There are also other commonly accepted conventions - like letters normally have a subject, a date, a signature. There are actually many assumptions built into our communication - all of which we can consider the "letter writing protocol".
Notice now that we have identified two protocols. One protocol, the postal protocol, establishes a set of rules and expectations for transport and delivery of letters. The second protocol, the letter protocol establishes a set of rules and expectations for understanding the contents of such letters.
Computer Protocols
What does this all have to do with computer networks? Computers need to communicate under a set of assumptions. All data in a computer systems is represented by 1's and 0's (see big vs little endian if you think this is straightforward). In order for computers to communicate, we'll need answers to the following:
- How are 1's and 0's encoded/decoded across the medium of transmission (copper wires, radio signals, fiber optics)?
- How is the encoded data's recipient to be represented?
- How can the data be routed to the receiver if not directly connected to the sender?
- How do we ensure the data arrives in reasonable condition (not corrupted)?
- How can the recipient interpret the data after it arrives?
Just like with our postal / letter example, all of these questions aren't going to be addressed by an single protocol. In fact, computer network protocols formally defines several layers of protocols to handle these sort of questions. The model is called the Open Systems Interconnnection - OSI model.
In the OSI model, the question of how 1's and 0's are encoded/decoded is considered part of the Physical and to some extent the Data link layers. These are the first two layers.
Layer 3 - the Network layer provides addressing, routing, and traffic control (think of that as an agreement on how to handle situations where the network is overloaded). This really covers question #2 and #3, and will be handled by the first protocol we will look at in detail - the Internet Protocol.
Our 4th question - how we ensure data arrives in reasonable condition - is actually more interesting than it might originally appear. Looking back to our postal/letter example - what do we mean by a letter arriving in reasonable condition? Clearly, if the letter itself is unreadable (perhaps water was spilled on it, and the ink has bled), it is unusable. This happens with 1's and 0's on the internet too - the physical transmission of these electronic signals is not perfect. Think about the trillions of 1's and 0's that are traveling through the air, through wires under the ocean, etc. Those bits will get flipped sometimes! This will result in a mangled data transmission.
How do we know if some of the bits have been flipped though? If you receive a physical letter in the mail that was somehow made unreadable, it's obvious to you - because the "letters" on the page are no longer letters - they are blobs of ink. In a computer system, if a bit gets flipped from a 1 to a 0, or a 0 to a 1, the data is still valid data. It's still 1's and 0's!
To drive this point home, let's imagine I'm sending you a secret number, the number 23. I send you the following binary data, which is the number 23 written as an 8-bit binary number.
00010111
Now let's say you receive this, but only after these signals travel the globe, and one digit gets flipped somehow.
01010111
You have received the number 87. The number 87 is a perfectly reasonable number! There is no way for you to know that an error has occurred!
Thankfully, we have ways of handling this kind of data corruption - checksums, and we'll cover it in a bit. This error detection is handled by the Network Protocol layer in the OSI model, and in our case will be part of the Internet Protocol.
As we will see however, detecting an error is not the same thing as handling an error. When an error occurs, what should we do? Do we have the sender resend it? How would we notify the sender? These questions are handled by the Transport layer, and will be handled by other protocols above the Internet Protocol in our case - either by Transmission Control Protocol or in some cases User Datagram Protocol.
The last question we have is #5, how can the recipient interpret the data after it arrives?. There's a lot backed in here. As you might recall from the postal/letter example, understanding the contents of a message requires a lot of mutual agreement. Is the letter written in a language the recipient can understand? Is there context to this letter - meaning, is the letter part of a sequence of communications? Does the letter contain appropriate meta data (subject, date, etc.)?
All of these issues are handled by layers 5-7 in the OSI model - Session, Presentation, and Application layers. For web development, the Hypertext Transfer Protocol protocol outlines all the rules for these layers. For other applications, other protocols define the rules - for example, email uses SMTP (Simple Mail Transfer Protocol) and file transfer applications use FTP (File Transfer Protocol) and SFTP (Secure File Transfer Protocol). Some applications even use their own custom set of rules, although this is less common. Generally, web applications will also layer their own logic and context over these protocols as well, unique to the particular use case of the application. For a web application, things like login/logout sequences, url navigation, etc. are clearly unique to the application itself. If users visit specific pages out of order, they might be "breaking the rules".
We won't cover physical networking in this book. It's a fascinating subject - understanding how 1's and 0's are actually transmitted across the globe - through the air (3G, 4G, 5G, LTE, etc), via satellites, ocean cables, etc - is a pretty heavy topic. When you start to think about the shear volume of data, and the speed at which it moves, it's mind boggling. However, as a web developer, the movement of 1's and 0's between machines is far enough removed from you that it's really out of scope. If you are interested, start by looking at the Physical Layer and then you can start working your way to all the various technologies.
As a web developer, you will be will be dealing with at least three protocols for communication in web development:
- Internet Protocol: Addressing, Routing, Error Detection
- Transmission Control Protocol: Error handling, reliable delivery of requests/responses, multiplexing
- HyperText Transfer Protocol: Encoding/Decoding of requests and response, and all of the rules of the web!
While the HyperText Transfer Protocol is the most important, the other two are still quite relevant, so we will tackle them in order.
The Internet Protocol
The Internet (capitalized intentionally) isn't the only network. It's the biggest network (by far), and really the only network used by the public today. However, if you went back in time to the 1960's, there was no reason to believe this would be the case. There were many networks - meaning there were lots of network protocols. Most of them were networks either within the defense industry or within academia. These networks weren't compatible with each other.
There was a need to have computers on different networks talk to each other - so there became a need for a standard protocol. In 1974, the Internet Protocol was proposed by V. Cerf and R. Kahn. It was quite literally devised as a protocol for communicating between networks - internet. The protocol grew in adoption, and along with a few other innovations (TCP, which we will see soon) eventually supplanted most other networking protocols entirely. In 1983, one of the largest and most important networks - ARPANET (Advanced Research projects Agency Network) switched over to the Internet Protocol. The network of computers that communicated using the Internet Protocol grew and grew. By the 1980's, the internet (not capitalized) was how people talked about the network of computers speaking the Internet Protocol. By the early 1990's, web technologies were running on top of the internet, and the rest is history.
So, what is the Internet Protocol? First, we'll call it simply IP from now on.
The first thing to understand is that the IP protocol is implemented primarily by the operating system on your computer. The IP protocol defines the fundamental format of all data moving through the internet. Thus, data encoded as IP data goes directly from memory to the network device of a computer - and out to the internet. The operating system generally limits access to network devices, and so you may interact and use the IP protocol via the operating systems API's.
IP provides two core facilities:
- Addressing
- Message Chunking & Error Checking
If you've heard of an IP address, then you know a little about IP already! We are going to go in reverse order though, starting out with message chunking - or what are referred to as packets.
IP Packets
IP messages are chunks of data that an application wishes to send to another. These messages are of arbitrary length, they are defined by the application doing the sending. An application transferring files might send an image as an IP message. A web browser might send an HTTP request as a message.
Sending arbitrary length 1's and 0's creates a bunch of problems. First, from a device design and software design perspective, dealing with fixed length chunks of data is always more efficient. Second, depending on the devices receiving (or more importantly, forwarding) the messages, arbitrarily long message may create electronic traffic jams, network congestion. To mitigate this, IP slices all messages into fixed length packets.
An internet packet is a fixed size chunk of binary data, with consistent and well defined meta data attached to it. This metadata will contain addressing information of both sender and receiver, along with a sequence number identifying where the packet is within the original larger message.
The Internet is, at it's core, a peer to peer network. Every machine on the internet is considered an IP host, and every IP host must be capable of sending, receiving, and forwarding IP packets. While your laptop or home computer is unlikely to be doing a lot of forwarding, forwarding IP packets is a critical design feature of the internet. Your computer is connected to a web of network switches that receive packets, determine whether they can connect directly to the intended recipient or which other switch is available to help locate the recipient. Each one of these switches moves up and down a topology (see below) that makes up the internet. Each packet might be forwarded by dozens of different network switches before it reaches it's final destination - just like the letter you send in the mail get's handled by many people before arriving at it's destination.
By slicing a message into packets, the network can route packets across the network independently - meaning packets belonging to the same larger message can take different paths through the network. This significantly aides in network congestion management and automatic load balancing, a primary function of all of the many millions of internet switches and routers making up the network. There's no analog to this in the postal/letter analogy - it's the equivalent of cutting your letter up into tiny pieces before sending :)
Let's look at a more concrete example. Suppose we are sending a 2.4kb image over IP. The minimum packet size that all IP hosts must be able to handle is 576 bytes. Hosts can negotiate sending larger packets, but at this point let's just assume packet sizes of 576 bytes.
Each packet will have a header attached to it, including IP version, total packet size (fixed), sender and recipient address, and routing flags such as sequence number. These packets (four of them, in the image below) are then sent across the network.

Note that in the image, packet 4 is smaller than the rest, it has the remaining bytes, less than 576. In reality, it will be sent as 576 bytes, with the remainder of the payload zeroed out.
Each packet flows through a network of switches. We will address a bit more on how these messages are routed across the network below, but for now the important concepts is that they travel through the network separately, and may take different paths. Packets belonging to the same message can arrive out of order (packet 3 may arrive at it's destination before packet 1). The IP protocol (the code implementing, at the operating system and device driver level) is responsible for re-assembling the packets in their correct order to form the resulting message on the recipients side.
Error Checking and Checksums
It's important to understand that whenever electronic data transmission occurs, we do have the possibility of errors. Computer networks send 1's and 0's over a medium, let's say radio frequency (wifi). Just like static when listening to your car's radio, transmission isn't perfect. As described above, when binary data transmission errors happen, the result is that a 1 is flipped to a 0 or a 0 is flipped to a 1. The result is still a valid binary data packet. In the best case, the resulting binary packet is nonsense, and easily understood to be corrupted. However, in most cases, the flipped bit results in a valid data packet, and it's impossible for a recipient to notice the bit flipping has occurred just by looking at the data.
For a concrete example, think about the IP message from above - and image. Images are sequences of pixels. Each pixel is three numbers, a value (typically) between 0 and 255 for red, green, and blue. For a reasonably sized image, there are thousands of pixels. Each pixel is barely perceptible to the human eye, but the composite gives us a nice crisp picture. What if one of those pixels was corrupted? One of the pixels that should look red, when it is received, is blue. How could a receiving program, which doesn't know what the image should look like, know that this has happened? The answer is, it's impossible - without some extra information.
The key to this problem is the concept of checksums. Checksums are hashes of a string of data. If you are familiar with has tables, you know the concept. For simple hash tables, you might take a large number and use the modulus operator to determine it's hash, and it's location in the table. Hashing functions exist to take arbitrarily long strings of data, and compute hash values from them that are substantially shorter.
Hashing functions are one way functions. They aren't magic, here's how it's done for all IP packets. Multiple (actually, infinite) inputs map to the same hash, however statistically speaking, the chances of two random inputs mapping to the same has is astonishingly low.
How does hashing relate to error detection? An IP packet has a payload (the actual data). This payload can be sent as input to the hashing function, resulting in a numeric value of just a few bytes. This checksum is then added to the IP packet header, and sent over the network.
When a machine receives a packet, the first thing it does is extract the payload data (a certain number of bytes) and the checksum from the packet. These are at well defined locations within the packet, so this part is quite trivial. Since all IP hosts use the same hashing function to compute checksums, the receiver can calculate the checksum of the received payload, and compare it with the checksum it found in the packet, which was computed by the sender originally.
There are 4 possible outcomes:
- One or more bits have been flipped in the area of the packet that held the checksum. This will result in the computed checksum being different than the checksum found in the packet, and the packet can be deemed corrupted.
- One of more bits have been flipped in the area of the packet that held the data payload. This will result in the computed checksum again being different than the checksum found in the packet, and the packet can be deemed corrupted. Note, there is an infinitesimally small chance that the bit flipping that occurred in the payload section resulted in a payload that still hashes to the same checksum. This would result in a false negative - the packet was corrupted by IP can't detected. Again, the chances of this actually happening are infinitesimally small.
- One ore more bits have been flipped in both the checksum and payload area of the packet. As in case #2, there is an incredibly small chance that this flipping results in the checksum changing such that the equally corrupted payload now hashes to the new checksum - however this is so unlikely we shouldn't even discuss it.
- No bit flipping occurs, the checksums match, the packet is accepted - hooray!
Recall that each IP message is sliced into many packets. If any packet within a message is corrupted, the entire message is dropped. This message drop can happen at the switch level (as it's moving through the network) or on the recipient machine. This is a hard drop - meaning that's it - the message is simply discarded. The sender is not notified. More on this to come :)
Ultimately, IP uses checksums to ensure the following: A message received by a program is the same message that was sent by the sending program.
Remember, however: IP does not ensure every message is received, and it does not ensure a sequence of messages are received in the same order they are sent.
IP Addresses
Thus far we've described what IP packets look like, to some extent. We've agreed that each packet has a header, and that the header has sender and receiver addresses. We have not defined what these addresses look like though. Let's work on that.
An IP address is made of four numbers, between 0 and 255, separated by dots (periods).
172.16.254.1
Actually, this is more specifically an IP v4 address. IP v6 addresses are more complex, and address the issue of potentially running out of IP v4 addresses (among other issues with v4). There is a lot to talk about regarding IP v4 and IP v6, but it's beyond the scope of a web development book - web developers will very rarely, if ever, deal with IP v6 addresses.
It's a 32-bit number, with each of the 4 numbers encoded as 8 bits. Every computer on the internet is assigned an IP address, however the vast majority are not assigned permanent IP addresses. When your laptop connects to a wifi switch, for example, it is assigned a temporary IP address which is unique within the sub network that wifi switch is managing. This is, in part, why we don't think we'll actually run out of IP v4 as quickly as we thought. Check out Network address translation for more on this.
Many machines, in particular machines that are frequently contacted by others, do have permanent of fixed IP addresses. These machines include routers and switches that act as gateways into other subnetworks, and servers (like web servers, database servers, etc). When your laptop or phone connects to your wireless service or wifi router, one of the first things it's doing is establishing/negotiating what machines it will use as the first hop for any outbound network messages. These first hop machines are often called gateways. Gateway machines maintain lists of other gateway machines, along with which subnetworks (subnets) they manage. Subnets are defined by ranges of IP addresses - for example, a particular subnet might be 172.0.0.0 through 172.255.255.255, and another machine within that subnet might manage IP addresses between 172.0.0.0 through 172.0.0.255. The idea is that routers and switches maintain registries of ranges of IP addresses they have connections with. When your computer sends a message to another computer, the message (IP packet) will be sent to your initial gateway machine, and then along any number of routers, being forwarded to eventually to the correct machine. Gateway machines actually maintain their registries through another protocol - the Border Gateway Protocol. Again, this is where we start to get outside of our scope, as a web developer, you will not often need to delve into the details of routing much further.
There are some special IP addresses that you should know about. Perhaps the most important is the loopback address - 127.0.0.1. 127.0.0.1 is always the current machine. If you send an IP packet to the loopback address, it will be received your own machine. You'll see this a lot in web development, because when you are coding things up, you are probably visiting your own machine via your browser! You will probably also use http://localhost for this too.
Some addresses are otherwise reserved - 0.0.0.0.0 is not used, 255.255.255.255 is a broadcast address, typically not used for anything related to web development. 224.0.0.0 to 239.255.255.255 are used for multicast (again, not used for most web development). There is more structure to IP addresses than we are discussing here - such as Class A, B, and C and their uses. You can actually see how the various ranges of IP addresses are allocated to top tier networks here, it's public data.
From our perspective as web developers, that's likely as far as we need to go in terms of addressing. IP addresses are numeric numbers, very similar to addresses on an postal envelope. Routers and switches are able to use IP addresses to route data through the network and to their destination.
Pro Tip💡 IP addresses are not the same as domain names. We are used to referring to machines using human readable names - https://www.google.com, https://webfoundationsbook.com, and so on. These domain names map to IP addresses, and they are transformed using publicly available and accessible databases. We'll cover this in the next chapter on HTTP and in particular, when we cover DNS.
IP Limitations
The Internet Protocol provides the baseline functionality of all internet applications, however it falls short in two specific areas.
- Error handling
- Multiplexing
First, we have the unresolved issue of error handling. IP detects corrupt messages, however it does not attempt to recover - it simple drops the messages. Since most applications communicate in sequences, dropped messages means there are gaps in communication. IP also makes no attempt to ensure messages arrive in order. Recall that each message you send is sliced into packets. Packets are small, to optimize their flow through the network. IP assembles packets back together on the recipient's end to form a coherent message, however two messages (each consisting of many packets) sent are not guaranteed to arrive in the same order. For example, if the first message was sliced into 100 packets (large message), and the second message was smaller (maybe 5 packets), it's very possible that all 5 packets within the second message arrive before each of the 100 packets from the first message. Out of order message may or may not be a problem for an application, but generally for web development it is.
The second problem is a bit more subtle. Imagine a scenario where you have two programs running on your computer. Each program is in communication with a remote machine (it doesn't matter if they are both talking to the same machine, or two different machines). What happens when an IP message is received?
Remember, the operating system is in charge of reading the IP message from the network device, and forwarding the message to the program that wants to read it. Which program wants to read the message?
IP actually doesn't define this, there is nothing within the IP message header that identifies the program on the specific machine that is waiting for the message. The operating system is not in the business of deciphering the contents of the message, and even if it was, it's difficult to imaging a fool-proof way for the operating system to already accurately figure out which program should receive the message. This example is describing multiplexing - the concept of having messages streaming into a computer and being forwarded to one of many programs currently running on the machine. It's sort of like receiving main to your house, and figuring out which one of your roommates should read it!
The layer up is the transport layer, and in web development this is nearly always handled by the Transmission Control Protocol - TCP. TCP will build on IP to address error handling and multiplexing.
Transport Layer
The transport layer (Layer 4 in the OSI model) picks up where the IP protocol leaves off. There are two concepts typically associated with Layer 4 - reliability and multiplexing
Reliability with Sequence numbers and Acknowledgements
Recall that each IP message is sliced up into packets and sent through the internet, with no regard for when each packet gets delivered. While IP assembles packets within messages in order (and drops messages that have missing or corrupt packets), it makes no attempt to ensure that entire messages are delivered in order. In some applications, this may be acceptable - however in most applications, this would be chaos.
Consider an application communicating keystrokes over a network. Each time the user presses a character, or a bunch of characters within a given amount of time, the sending application fires them over to a receiver, responsible for saving the characters to a remote file. If message are arriving out of order, then characters will end up being saved to disk out of order. It's pretty clear that won't work!
Here's a toy example, with a hypothetical API for sending and receiving messages. It further illustrates the concern.
// This is the sender code,
send(receiver_ip_address, "Hello");
send(receiver_ip_address, "World");
// This is the receiver code
// Imagine recv blocks, waiting until the machine receives a message
// and then recv decodes the IP message (it's packets) and returns the
// message.
message1 = recv();
message2 = recv();
print(message1); // We do NOT know if message 1 will be "Hello" or "World"!
print(message2); // They could have arrived out of order!
Let's pause for a moment and remember where the IP protocol is implemented. The send and recv functions used in the example above are hypothetical, but they mimic operating system API's that we will use to send and receive data. Notice that in this example, send would need to do the slicing into packets, and attaching IP headers to each packet, including the checksum and sequence number - for each message. Likewise, recv would need to manage the process of assembling all the packets and doing error checking before returning the message to the program that called recv. Clearly recv would also potentially either return an error, or throw an exception of some sort if no message was received after some period of time, or if a message was received by corrupted.
Back to the ordering problem. There is an obvious solution to this, and it is actually already used within IP for packets within a message. We can simply attach a sequence number to each message that we send. This would allow us to detect, on the receiving end, when something has arrived out of order. However, this also means that there needs to be some start (and end) of a sequence of messages between two machines - what some might call a session. At the beginning of the session, the first message is assigned a sequence number of 0, and then after sending each message, the current sequence number is incremented. The session, in this respect, has state. The sequence number is part of the message that is sent using IP, it's inside the IP payload.
The code might look something like this:
// Sender code
session = create_transport_session(receiver_ip_address)
session.send("Hello");
session.send("World");
// Receiver code
session = accept_connection();
// Recv still blocks, but now it also determine if something arrives
// out of order, because there is a sequence number associated with the
// session. If we receive "World" first, recv won't return - it will wait
// until "Hello" arrives, and return it instead. Then the next call to receive
// will return "World" immediately - since it already arrived and was cached.
message1 = session.recv();
message2 = session.recv();
print(message1); // Will definitely be "Hello"
print(message2); // Will definitely be "World"
This is powerful. With the operating system implementing a Transport layer protocol for us, we not only can deal with out of order messages, we can also handle missing messages. As discussed before, IP drops messages that are corrupted. With our sequence number solution, we can detect when we are missing a message. For example, we can see (on the receiving end) that we've received a message with sequence number 4 before receiving one with sequence number 3 - and wait for 3 to arrive. However, a message with sequence number 3 may actually never arrive if it was corrupted along the way. Could we ask the sender to resend it?
It turns out, it is more efficient (somewhat surprisingly) to have the receiver actually acknowledge every message received, rather than asking the sender to resend a missing message. This is because in order to avoid asking for unnecessary resends the receiver would need to wait a long time - given the message may be en route. It also makes sense to use an acknowledgement scheme rather than a resend request because it is possible that the receiver misses multiple messages. Using the previous example, what if we not only miss message 3, but message 4 also. What if at that point, the sender is done sending! The receiver will never receive a message 5, and never know it missed messages 3 and 4!
The actual solution to the reliability problem is as follows:
- Each message gets a sequence number
- Upon receipt, the receiver sends an acknowledgement to the sender.
- The sender expects an acknowledgement within a specific time window (we'll discuss details soon), and if it doesn't receive it, it resend the message. After a specified number of resends without an acknowledgement, the connection is deemed lost.
- Receivers will cache any out of order messages received until all messages with sequence numbers less than the out of order message are received, or the connection times out.
It's interesting to note, it's possible that the acknowledgement never makes it to the sender, for the same reason it's possible the original message didn't make it to the receiver. That's ok, the sender just resends. The receiver will ignore receipt of a message it already has, since it's trivial to detect a duplicate based on the sequence number.
It's important to understand the above lays out a conceptual strategy for allowing for reliable data transmission over IP, but there are lots of optimizations that can be made. Stay tuned for more on this below.
Multiplexing with Port Numbers
Port numbers are a simple concept, but are foundational to application programming over networks. Think about how postal mail is delivered via the postal system. Imagine a letter, being sent across the country. It arrives at your house based on the address - the street number, town, postal code, etc. The address relates to the physical location where the mail should be delivered. Layer 3 (the IP Protocol) does a lot of the work here - it identifies physical machines, and routes data traffic through the network so it reaches the right machine.
However, when mail gets delivered to your house, there's another step. Unless you live alone - you probably need to take a look at the name listed on the envelope before you open it. If you have a roommate, you probably shouldn't open their mail - and vice versa. Well, network traffic is sort of like this too! On your computer, right now, you probably have a few applications running that are receiving network data - your web browser, maybe an email client, a game, etc. As network traffic comes into your computer over the network device, the underlying operating system software needs to know which application should see the data.
Port numbers are just integers, and they are abstract (they don't physically exist). They serve a similar purpose as the name of the person on a mail envelope - they associate network data being transmitted over IP with a specific stream of data associated with an application. Your web browser communicates with web servers over a set of port numbers, while your email client uses a different port number, and your video games use others. Applications associate themselves with port numbers so the operating system can deliver received data to the right application.
Port numbers facilitate multiplexing, in that they allow a single computer to have many applications running, simultaneously, each having network conversations with other machines - as all network messages are routed to the correct application using the port number.
Just like with sequence numbers, port numbers are associated with a "session" - a connection managed in software between two computers. The session will have sequence numbers, acknowledgement expectations, and the port number of the receiver (and sender).
Sockets
We've been using the term "session" to represent a stateful software construct representing a connection between two machines. While the term make sense, it's not actually what is used. Instead, we call this a socket. A socket, across any operating system, is a software construct (a data structure) that implements the IP + Transport Layer protocol. There are two basic types of sockets, which correspond to the most commonly used transport layer protocols: TCP and UDP.
TCP - the Transmission Control Protocol is by far the most commonly used of the two. TCP layers reliability and multiplexing on top of IP using sequence numbers, acknowledgements, and port numbers. UDP - the User Datagram Protocol, doesn't go quite a far. UDP only adds multiplexing (port numbers), and does not address reliability. We will talk a bit more about UDP in the next session, but we don't use it much in web development.
Transmission Control Protocol
TCP implements what we described above, and it implements it extremely well. TCP isn't really an addon to the IP protocol, it was developed originally by the same people, at the same time. It was always obvious we needed reliability and multiplexing, it's just that it makes sense to divide the implementation into two protocols to allow for some choice (for example, to use UDP instead for some applications).
TCP is far more complex than what was described above, in that it uses a more sophisticated acknowledgement scheme that can group acknowledgements to reduce congestion. It also uses algorithms to more efficiently time resends, using a back off algorithm to avoid flooding already congested networks (congested networks are the primary reason packets are dropped, so further flooding is counterproductive). The technical details of the algorithms used in TCP are very interesting, and you can start here to do a deep dive - however they aren't necessary for web development. Simply understanding the basic concepts of how TCP ensures reliability and multiplexing is sufficient.
The Internet Protocol and Transmission Control Protocol are core to the internet - it simply wouldn't exist without them. The two protocols are generally simply referred to as the "TCP/IP" stack.Operating systems expose API's for communicating via TCP/IP via sockets. We now turn our attention to learning how to truly program with them.
Socket Programming
It's possible to write applications directly on top of IP, but it's not common. The transport layer - TCP in our case - makes for a much more convenient programming abstraction. TCP is a connection-oriented protocol that uses ports and sequence numbers, along with acknowledgement and resend strategies, to create reliable and (somewhat) private communication between two applications running on (usually) two different machines. The protocol itself is so standardized, that rather than implementing it yourself, you typically use your operating systems's APIs (either directly or indirectly) to handle the details for you. Most, if not all, operating systems comes with an API that implement the "TCP/IP Stack" - meaning they provide an API for programmers to work with TCP over IP. This API is usually exposed via C libraries, however most other programming languages provide developers a higher level API in the host language which wraps the C libraries of the operating system.
Regardless of which language you interact with the TCP/IP stack through, one single concept prevails: the socket. In network programming, a socket refers to a connection between two machines over a port number. In the case of a TCP socket, the socket consists of all of the following:
- Port number of each machine (the two peers)
- Sequence numbers (bi-directional)
- TCP acknowledgement timer configuration, flow control established during TCP handshake
Notice, a socket is really just "state". It's not a physical connection, it's the book-keeping associated with implementing TCP on top of IP. In some languages, sockets are naturally represented by classes and objects, while in others they are represented by file descriptors or handles. Regardless, the operating systems is generally the player that maintains all the book-keeping - as it's the one that is implementing the IP and TCP protocols. The software representation of the socket is your interface into all of this functionality.
Side Note: What about UDP?
TCP isn't the only transport layer (Layer 4) protocol built on top of IP. UDP - User Datagram Protocol - adds some convenience on top of IP (Layer 3), but not quite as much as TCP does. While TCP is a connection oriented protocol, which establishes sequence numbers for communication, the UDP protocol is connectionless. UDP adds the concept of port numbers on top of IP (as TCP does), but peers can send data to target machines without any initial "handshake". This means communication can be faster - there's less overhead - but the tradeoff is that UDP does not include a mechanism to recognize lost or out-of-order communication, or the ability to correct these problems. This is because UDP does not add a concept of sequence numbers, which allows for any detection of lost/out-of-order packets. When working with UDP, the application developer must handle these concepts (if necessary) at the application level.
It's fair to ask - why does UDP exist if it doesn't detect or resolve lost or out of order packets? The answer is pretty simple - there are times where you simply don't need reliability, but you do want to send / receive data via specific port numbers. The IP protocol sends data between machines, but Layer 4 Transport Protocols (TCP and UDP) establish port numbers to allow for separate streams of communication. This allows multiple applications on a single machine to receive data from different machines.
UDP is a great alternative for applications that are streaming updates. For example, a networked video game may be sending a player's physical location to peer machines. In this case, each individual position update is not critical - if one is lost, it's better to receive the next update, rather than try to get the last update resent. Likewise, when implementing video or audio communication systems - where video content is streaming across the internet - a dropped frame or audio clip shouldn't be resent - it's better to simply receive the next one. These types of applications need port numbers (separate streams of data communication), but they don't need the detect/resend functionality of TCP. UDP is enough, and since it's more efficient, applications benefit from increased network performance.
Pro Tip💡: If you find yourself implementing reliability control on top of UDP, take a step back. TCP is used by almost every single networked application in the world that needs reliable communication. It's optimized. It works, and it works well. Don't implement your own reliability protocols unless you have an incredibly good reason to (and I'd respectfully argue that you probably don't!). If you need reliability, use TCP. If you aren't sure if you need reliability, use TCP. If you are really sure you don't need reliability, then use UDP.
A Server, A Client and a Connection
The terms server and client are loaded terms in computer networking. They mean a lot of different things, in a lot of different contexts. For TCP/IP networking, the two terms really mean something very simple however:
- The Server - the machine that accepts new connections when contacted by another machine.
- The Client - the machine that initiates contact with a server to establish a connection.
Notice what the above does not say. There is no contextual distinction between what a server or and client actually do, once they connect with each other. There is no expectation that further communication is in a specific direction (server sends things to client, or vice versa), bi-directional, or otherwise. There is an implied difference in the two machine's role however: the server usually accepts and can maintain connections with several clients simultaneously, while clients generally talk to one server at a time (although there are many exceptions to this pattern).
So, how does a client establish a connection? It all starts with the client application knowing which machine it wants to talk to, and through which port number.
Let's outline an example sequence, and then we will discuss how the client might obtain this information a bit later.
The Server: Example
The server application is running on a machine with an IP address of 129.145.23.122. It listens for TCP connections from clients on port number 3000. This is commonly written as 129.145.23.122:3000. In the next section, we will cover how this listening action is performed in C code, and then in some other languages.
The Client: Example
The client application is running on a different machine, with an IP address of 201.90.1.17. Critically, it knows the server's IP address and the port number - it knows that it will be connecting to 129.145.23.122:3000.
Making the Connection
The client will invoke an API call to connect to the server - passing the 129.145.23.122:3000 IP/port information to the appropriate library call.
This library call (or sequence of calls, depending on the programming language and operating system) will do a few things:
- It will request from the operating system a free port number on the client machine. This port number is not known ahead of time - and need not be the same every time the application runs. It won't be the same for all clients. It's required, because eventually the server will need to send data to the client machine, and it will need a port number to do that - but the client will tell the server which port to use during the connection process, so it doesn't need to be known ahead of time.
- The operating system's networking code will invoke the appropriate network devices to send a TCP connection request to the server (IP address 129.145.23.122, port 3000). This connection request is sent as a set of IP packets, using the IP protocol. The server, which must be listening on port 3000, will receive this data and exchange several more messages with the client machine. This handshake exchanges information such as (1) client's socket port number, (2) sequence number starting points (probably 0 for each direction), (3) acknowledgement expectations (how long to wait for acknowledgements, how frequent they should be, etc.) and any other information associated with the implementation of TCP.
- Most importantly, the handshake process includes a critical step on the server side. The server, which was listening for requests on port 3000, requests it's operating system to allocate a new port number to dedicate to communicating with this particular client. This port number, much like the client's port number, is transient - it will be different for every client connection, and every time the server runs. This port number is sent to the client during the handshake data exchange.
To summarize:
- The client initiates the connection by sending data to the server at the server's IP address and listening port number.
- The client sends the server the port number that the server should use when sending data to the client.
- The server creates a new port number, and sends this port number to the client so the client knows which port number to talk to the server over from now on.
At this point, we can consider the socket connected. The socket is a connection - it contains the IP address of both machines, the port numbers each machine is using to communicate for this specific connection, and all the TCP bookkeeping data such as sequence numbers and acknowledgement parameters.
From this point forward, when the client sends data to the server, it sends it via TCP to IP address 129.145.23.122 on port 8432. When the server sends data to the client, it sends to IP address 201.90.1.17 on port 5723. Port numbers 8432 and 5723 are arbitrary and dynamically generated at run time - only the listening port on the server (3000) must be known ahead of time.
Key Point 🔑: The creation, by the server, of a new port number for the new connection is something that is often missed by students. The server is listening for new connections on port 3000 - but once a connection is created, it does not use port 3000 for communicating with the newly connected client - it uses a new port number, dynamically generated for the client. This allows the server to now continue to listen for ADDITIONAL clients attempting to connect over port 3000.
How does the client know which port to connect to?
You might be wondering - how does the client know to contact the machine with IP address of 129.145.23.122, and how does it know it is listening on port 3000? The short answer is, it just does!
A client must know which machine it wants to connect to, and what port number it is accepting connections on. When two applications are connecting to each other, written by the same programmer, or programming team - this information is often just baked into the code (or, hopefully, configuration files).
Sometimes, the client application will just ask the user for this information - and the user is responsible for supplying it.
In other circumstances, port numbers might be known through convention. For example, while email servers could listen on any port number, most listen on either port 25, 587, or 465. Why those port numbers? Well, that's harder to answer - but the reason's are historical, not technical. We'll learn a few, but there are a lot. These conventional port numbers are more often referred to as well-known port numbers.
Just remember, client' initiate connections to servers. Clients need to know the server's address and port - somehow. Servers don't need to know anything ahead of time about clients - they just accept new connections from them!
Echo Client and Server
In this section we will put everything we've learned about TCP/IP together, and implement a simple networking application - the echo server and client. The echo server/client is a set of (at least) two applications. The echo server listens for incoming TCP connections, and once a connection is established, will return any message sent do it by the client right back to the very same client - slightly transformed. For this example, the client will send text to the server, and the server will send back the same text, capitalized.
Here's the sequence of events:
- Echo server starts, and begins listening for incoming connections
- A client connects to the server
- A client sends text via the TCP socket (the text will be entered by the user)
- The server will transform the text into all capital letters and send it back to the client
- The client will receive the capitalized text and print it to the screen.
If the client sends the word "quit", then the server will respond with "Good bye" and terminate the connection. After terminating the connection, it will continue to listen for more connections from additional clients.
Implementation - C++ Echo Server
Most of the code in this book is JavaScript. It's important to understand that the web, networking, and TCP / IP are all language agnostic however. Applications can communication with TCP/IP no matter what programming language they are written in, and there is no reason to ever believe the server and client will be written in the same programming language.
To reinforce this, we'll present the server and client in C++ first. The C++ code presented here might seem really foreign to you - don't worry about it! It's specific to the POSIX environment (actually, MacOS). Don't worry about understanding the code in detail - instead, closely look at the steps involved. We will then substituted the C++ client with a JavaScript implementation, and show how it can still talk to the C++ echo server. Finally, we'll replace the C++ server with a JavaScript server.
// Headers for MacOS
#include <unistd.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <netdb.h>
// Standard C++ headers
#include <iostream>
#include <string>
#include <thread>
const u_short LISTENING_PORT = 8080;
// Capitalizes the input recieved from client
// and returns the response to be sent back.
std::string make_echo_response(std::string input)
{
std::string response(input);
for (int i = 0; i < response.length(); i++)
{
response[i] = toupper(response[i]);
}
return response;
}
// The client connection is handled in a new thread.
// This is necessary in order to allow the server to
// continue to accept connections from other clients.
// While not necessary, this is almost always what servers
// do - they should normally be able to handle multiple
// simulusatneous connections.
void do_echo(int client_socket)
{
std::cout << "A new client has connected." << std::endl;
while (true)
{
char buffer[1024];
std::string input;
int bytes_read = read(client_socket, buffer, 1024);
if (bytes_read <= 0)
{
std::cout << "Client has disconnected." << std::endl;
break;
}
input = std::string(buffer, bytes_read);
std::cout << "Received: " << input << std::endl;
std::string response = make_echo_response(input);
std::cout << "Sending: " << response << std::endl;
// Send the message back to the client
write(client_socket, response.c_str(), response.length());
if (response == "QUIT")
{
std::cout << "QUIT command received. Closing connection." << std::endl;
break;
}
}
// Close the client socket
close(client_socket);
}
int main()
{
// Create the listening socket
// This call creates a "file descriptor" for the socket we will listen
// on for incoming connections.
int listening_socket = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// Next we initialize a data structure that will be used to attach
// the listening socket to the correct port number, along with some
// other standard attributes.
struct sockaddr_in ss;
memset((char *)&ss, 0, sizeof(struct sockaddr_in));
ss.sin_family = AF_INET;
ss.sin_addr.s_addr = inet_addr("127.0.0.1"); // Just accept local connections
// Otherwise we need to deal with
// firewall/security issues -
// not needed for our little example!
ss.sin_port = htons(LISTENING_PORT); // port number
// Now we bind the listening socket to the port number
// Should check that bind returns 0, anything else indicates an
// error (perhaps an inability to bind to the port number, etc.)
bind(listening_socket, (struct sockaddr *)&ss, sizeof(struct sockaddr_in));
// Now we tell the socket to listen for incoming connections.
// The 100 is limiting the number of pending incoming connections
// to 100. This is a common number, but could be different.
// Should check that listen returns 0, anything else indicates an
// error (perhaps the socket is not in the correct state, etc.)
listen(listening_socket, 100);
// At this point, the server is listening, a client can connect to it.
// We will loop forever, accepting new connections as they come.
std::cout << "Listening for incoming connections on port "
<< LISTENING_PORT << std::endl;
while (true)
{
// Accept a new connection
struct sockaddr_in client;
socklen_t len = sizeof(struct sockaddr_in);
// The accept call will block until a client connects. When a client connects,
// the new socket connected to the client will be returned. This is a different
// socket than the listening socket - which remains in the listening state.
int client_socket = accept(listening_socket, (struct sockaddr *)&client, &len);
// Now we have a new socket connected to the client. We can handle this
// connection in a new thread, so that the server can continue to accept
// connections from other clients.
std::thread echo_thread(do_echo, client_socket);
echo_thread.detach();
}
}
Implementation - C++ Echo Client
// Headers for MacOS
#include <unistd.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <netdb.h>
// Standard C++ headers
#include <iostream>
#include <string>
using namespace std;
// Notice that this lines up with the listening
// port for the server.
const u_short SERVER_PORT = 8080;
int main()
{
// Create the socket that will connect to the server.
// sock is a "file descriptor".
int sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// Next we initialize a data structure that will be used
// to connect to the server - it contains information about
// which IP address and port number to connect to.
struct sockaddr_in ss;
memset((char *)&ss, 0, sizeof(ss));
ss.sin_family = AF_INET;
// This is the IP address of the server. For this simple example,
// the server is running on the same machine as the client, so "localhost"
// can be used. If the server was elsewhere, we can use the same code, but
// with the name of the machine (or IP address) replacing "localhost".
struct hostent *sp; // struct to hold server's IP address
sp = gethostbyname("localhost");
memcpy(&ss.sin_addr, sp->h_addr, sp->h_length);
// This is the port number of the server. This must match the port number
// the server is listening on.
ss.sin_port = htons(SERVER_PORT);
// Now we connect to the server. This call will return when the connection
// is established, or if it fails for some reason.
int result = connect(sock, (struct sockaddr *)&ss, sizeof(ss));
if (result != 0)
{
std::cerr << "Error connecting to server " << strerror(errno) << endl;
return result;
}
while (true)
{
// We are connected (or write will fail below)
int n;
char buffer[1024];
string echo_input;
string echo_response;
// Read a message from the user
cout << "Enter a message: ";
getline(cin, echo_input);
// Send the message to the server, should always check
// that n == echo_input.length() to ensure the entire message
// was written...
cout << "Sending: " << echo_input << endl;
n = write(sock, echo_input.c_str(), echo_input.length());
// Read the message from the server. Should check if n < 0,
// in case the read fails.
n = read(sock, buffer, 1024);
echo_response = string(buffer, n);
cout << "Received: " << echo_response << endl;
if (echo_response == "QUIT")
{
break;
}
}
// Close the socket
close(sock);
}
Implementation - JavaScript Echo Client
We can implement a compatible client in any language, there is no need for client and server to be written in the same language! If you aren't familiar with JavaScript, or callback functions, then the following code may seem a bit mysterious to you. Rather than focusing on those mechanics, try to focus on what's happening with sockets - you should notice the similarities between the C++ example and this. The main difference is that callback take the place of synchronous loops, and the Node.js interface for sockets is quite a bit simpler than the C++ version.
The easiest way of thinking about the difference between the C++ and JavaScript versions is that JavaScript is event driven. In the C++ version, everything is sequential - we make function calls like getline, connect, write and read. Everything executes in order, and we use loops to do things over and over again.
In the JavaScript version, we identify events - when the socket gets connected, when the user types something in, when a response is received from the server. We write functions (usually anonymous) that contain code that executes whenever these events occur. Notice in the code below there are no loops - we simply specify, send the entered text whenever the user types something and print the response and prompt for more input whenever the server response is received. Those callbacks happen many times - and the sequence is kicked off by connecting to the server.
We will talk a lot about callback in JavaScript in later chapters - don't get too bogged down on this now!
// The net package comes with the Node.js JavaScript environment,
// it exposes the same type of functionality as the API calls used
// in C++ and C implementations - just wrapped in a more convenient
// JavaScript interface.
const net = require('net');
// This is also part of Node.js, it provides a simple way to read
// from the terminal, like the C++ iostream library.
const readline = require('readline');
// Notice that this lines up with the listening
// port for the server.
const SERVER_PORT = 8080;
// This just sets up node to read some lines from the terminal/console
const terminal = readline.createInterface({
input: process.stdin,
output: process.stdout
});
// This is a callback function. Whenever a user types anything on stdin,
// and hits return, this anonymous function gets called with the text
// that was entered. The text is sent to the socket.
// We'll cover callbacks later in depth - but for now, just know
// this is a function that gets called when a user types something. It's
// not getting called "now", or just once - it gets called whenever a line
// of text is entered.
terminal.on('line', function (text) {
console.log("Sending: " + text);
client.write(text);
});
// Now we create a client socket, which will connect to the server.
const client = new net.Socket();
client.connect(SERVER_PORT, "localhost", function () {
// Much like terminal.on('line', ...), this is a callback function,
// the function gets called when the client successfully connects to
// the server. This takes some time, the TCP handshake has to happen.
// So the "connect" function starts the process, and when the connection
// process is done, this function gets called.
// We just prompt the user to type something in and when they do, the
// terminal.on('line', ...) function above will get called.
console.log("Enter a message: ");
});
// And another callback - this time for when data is recieved on the socket.
// This is the server's response to the message we sent.
// We quit if it's time to, otherwise we prompt the user again.
client.on('data', function (data) {
console.log('Server Response: ' + data);
if (data == "QUIT") {
// This closes the socket
client.destroy();
// This shuts down our access to the terminal.
terminal.close();
// And now we can just exit the program.
process.exit(0);
} else {
console.log("Enter a message: ");
}
});
Implementation - JavaScript Echo Server
We can write a server in JavaScript too, and the C++ and JavaScript clients can connect to it - even at the same time. In this example, Node.js's net library along with it's asynchronous callback design really shines. We don't need to deal directly with threads, while still retaining the ability to serve many clients simultaneously.
// The net package comes with the Node.js JavaScript environment,
// it exposes the same type of functionality as the API calls used
// in C++ and C implementations - just wrapped in a more convenient
// JavaScript interface.
const net = require('net');
const LISTENING_PORT = 8080;
// The concept of "server" is so universal, that much of the functionality
// is built right into the Node.js "createServer" function. This function call
// creates a socket - we are just providing a function that will be called
// (a callback) when a new client connects to the server.
const server = net.createServer(function (socket) {
// A new socket is created for each client that connects,
// and many clients can connect - this function will be called
// with a different "client" socket for any client that connects.
console.log("A new client has connected.");
// Now we just add a callback to implemenent the echo protocol for
// the connected client - by looking at what the client sends is.
socket.on('data', function (data) {
const input = data.toString('utf8');
console.log("Received: ", input);
response = input.toUpperCase();
console.log("Sending: " + response);
socket.write(response);
if (response == "QUIT") {
console.log("QUIT command received. Closing connection.");
socket.destroy();
}
// otherwise just let the socket be, more data should come our way...
});
socket.on('close', function () {
console.log("Client has disconnected.");
});
});
// The last little bit is to tell the server to start listening - on port 8080
// Now any client can connect.
console.log("Listening for incoming connections on port ", LISTENING_PORT);
server.listen(LISTENING_PORT);
It's actually a pretty amazing little program - in just a few lines of code we have implemented the same TCP echo server as we did using over 100 in C++!. It's the same functionality though, and completely interoperable!
Echo is just a protocol
We've discussed the Internet Protocol as a Layer 3 network layer protocol. It's a standard way of addressing machines, and passing data through a network. We've discussed TCP as a Layer 4 transport layer protocol. TCP defines ports to facilitate independent streams of data mapped to applications, along with reliability mechanisms. In both cases, protocol is being used to mean "a set of rules". IP is the rules of addressing and moving data, TCP is the rules of making reliable data streams.
Echo is a protocol too, but it's a higher level protocol. It defines what is being communicated (text gets sent, capitalized text gets returned) - not how. It also defines how the communication is terminated (the client sends the word "quit"). Echo has aspects of OSI model's Layers 5-7, but it's probably easier to think of it as an application layer protocol.
Notice, any application that speaks the "echo protocol" can play the echo game! Go ahead and check out all of the examples in the /ch2 directory of the code repository - included are implementations in Python and Java to go along with JavaScript and C++. They all play together. Taking a look at examples in languages you already know might help you understand the mechanics of sockets a bit better!
The Protocol of the Web
The protocol of the web defines what web clients and web servers communicate. Normally, TCP / IP is used at the network and transport layer - but as we've seen, that doesn't describe what is sent - just how. In order for all web clients and servers to be able to play happily together, we need an application layer protocol. This protocol is the subject of the next chapter - the HyperText Transfer Protocol - HTTP.
Just like for the echo server and client, HTTP isn't about a specific programming language. Any program, regardless of the language it is written in, can speak HTTP. Most web browsers (clients) are written in C, C++ (and some partially in Rust). Web servers are written in all sorts of languages - from C, Java, Ruby, and of course Node.js / JavaScript!
Hypertext Transfer Protocol
Hypertext
We all know what text is. It's not a stretch from text to the concept of a text document - we're all pretty familiar with that idea too. One thing about text documents (think about paper documents) is that they often refer to other documents. These references might be footnotes, citations, bibliographies, or just embedded as quotations in the text.
Hyper, in mathematics, means extension. The concept of somehow extending text documents - such that you could instantaneously reach things such as references - was inspired by pre-computer technologies like microfilm. The term hyper-text first appeared in an article written by Vannevar Bush in 1945, in which a futuristic device called the Memex allowed a user to instantly skip and link to content made of chains of microfilm frames. In the 1960's, this concept was closer to reality through digital document systems. Ted Nelson coined the terms HyperText along with HyperMedia (referring to a systems where not just text could be linked and skipped to, but also images, sound, and video).
The concept of having links within documents that could be traveled instantaneously is a powerful one. It's not just that a reader can quickly skip to different documents (and then return to the original), but documents could embed other documents and media from different sources. If you consider pre-digital information systems (i.e. books, card catalogs, and libraries), you can see how much of a leap this is.
There is a lot more history to hypertext. You are encouraged to do some research, but let's move on to how hypertext moved from an emerging idea to the technology that we use every single day.
While working at CERN in 1989, Tim Berners-Lee proposed a project to link text documents already on the internet together, called the WorldWideWeb. The core of the proposal was a protocol for addressing documents, requesting documents over TCP, and delivering documents. Crucially, within these documents was a way to embed addresses of other documents. This allowed the software rendering the document to allow a user to ask it to display that resource. We of course recognize this as a link. We use them every day :)
If you haven't put it together yet, the WorldWideWeb project is where we got the www from, and documents that were available on this system were written in an early version of HTML - which stands for Hper Text Markup Language. The "software" that rendered these documents was the first web browser. Some of the very first web browsers were text based, the Line Mode Browser and Lynx are some of the most influential. Berners-Lee is also credit with creating the first web server at CERN, to serve the documents to the first browsers.
HTTP Protocol
The glue between the browser and the server is the protocol that they use to address, request, and deliver documents (which are more accurately called resources, since they need not be text). The protocol is the HyperText Transfer Protocol. Just like the "echo" protocol we saw in the last chapter, it's just a text-based protocol. Text is is sent from the client (the web browser), interpreted by the server, and text is sent as a response. The difference is that the text is much more structured, such that it can include metadata about the resources being requested and delivered, along with data and resources themselves.
The HTTP protocol has proven to be a remarkably powerful method of exchanging data on networks. It is fairly simplistic, but is efficient and flexible. At it's heart is the concept of resources, which are addressable (we'll see this referred to as a URL - universal resource locator). If we think of HTTP as a language, then resources are the nouns - they are the things we do things with. The verbs of HTTP are the things we do - the requests web browsers (clients) perform on resources. The adjectives are meta data that we use to describe both nouns and verbs - we'll soon recognize these as request and response headers.
The Nouns of HTTP - URLs and Domain Names
We can't build a hypertext system without a way of addressing resources - whether they are text or some other form of media. We need a universal way of identifying said resources on a network. In the previous chapter, we learned that the Internet Protocol has an addressing scheme for identifying machines on the internet. We also learned that TCP adds a concept of a port number, which further identifies a specific connection on a machine. We learned that when creating a socket, we needed to use both - and we used the format ip_address:port - for example, 192.45.62.156:2000.
The descriptors of IP and TCP get us partially towards identifying a resource on the internet - the IP address can be the way we identify which machine the resource is on, and the port number helps identify how to contact the server application running on that machine that can deliver the resource to us. There are two components that are not described however:
- Which protocol should be used to access said resource?
- Which resource on the machine are we trying to access?
By now, you should know that the protocol we will be dealing with is HTTP. The protocol is also referred to as the scheme, and can be prepended to the address/port as follows:
http://192.45.62.156:2000
The above is telling us that we are looking to get a resource from the machine at IP address 192.45.62.156, which has a server listening on port 2000, capable of speaking the HTTP protocol. http:// isn't the only scheme you may have seen - you've probably noticed https:// too. This is a secure form of HTTP which is simply HTTP sent over an encrypted socket. Secure HTTP is still just HTTP, so we won't talk much about it here - we can make HTTP secure simply by creating an encrypted socket - and we will do so in future chapters.
By the way, there are lots of schemes - most of which map to protocols. It's not unheard of to see ftp://, mailto://, and others. Here's a fairly complete list.
As for #2, which resource, we borrow the same sort of hierarchy mental model as a file system on our computer. In fact, the first web servers really simply served up documents, stored on the machine's file system. To refer to a specific file on in a file system, we are fairly used to the concept of a path, or file path. The path /a/b/c/foo.bar refers to a file called foo.bar found in the c directory, which is in the b directory, inside the a directory, which is found at the root of the file system. When used to identify an http resource, the "root" is simply the conceptual root of wherever the web server is serving things from.
Therefore, to access a resource under the intro directory called example.html on the machine with address 192.45.62.156, by making a request to a server listening on port 2000 speaking http, we can use the following universal resource locator:
http://192.45.62.156:2000/intro/example.html
A Universal Resource Locator, or URL is the standard way to identify a resource on the web. We'll add additional components to it later, but for now it's just scheme://address:port/path.
The URL http://192.45.62.156:2000/intro/example.html might look sort of familiar, but URLs that we normally deal with don't have opaque IP addresses in them, at least typically. They also don't normally have port numbers.
First off, let's discuss port numbers quickly. As we discussed in the previous chapter, clients must always know the port number they need to connect to when initiating a connection. While it's always OK to specify them in a URL, we can also take advantage of well known or conventional port numbers. On the web, http is conventionally always done over port 80, and https (secure http) is done over port 443. I know, this feels random. It sort of is. Thus, whenever we use scheme http:// and omit the port number, it is understood that the resource is available on port 80. When https:// is used, 443 is assumed.
Pro Tip💡 Do not, under any circumstance get confused... HTTP does not have to use port 80. It can use any port you want. HTTP is what you send over a socket, it doesn't care which port that socket is associated with. In fact, on your own machine, it is unlikely you will easily be able to write a program that creates sockets on ports 80 or 443, because typically the operating system safeguards them. As developers, we often run our web software on other ports instead - like 8080, 8000, 3000, or whatever you want. Typically these port numbers can be used by user programs on a machine, and are firewalled to avoid external (malicious) connections. A program that works on port 8080 will work on port 80, you just need to jump through some security hoops!
So, let's revise our example URL to use port 80
http://192.45.62.156:80/intro/example.html
This URL is perfectly valid, but since port 80 is the default port for HTTP, we could also write the following:
http://192.45.62.156/intro/example.html
Domain Name Service
If URLs required people to remember the IP address of the machines they wanted to connect to, it's fair to assert the WorldWideWeb project wouldn't have become quite so mainstream. Absolutely no one wants to use IP addresses in their day-to-day life. Rather, we would much prefer to use more human-friendly names for machines. This brings us to the concept of domain name.
Domain names are sort of structured names to refer to machines on the internet. We say sort of because a given domain name might not actually correspond to just on machine, and sometimes one machine might be reachable from several domain names. Conceptually however, it's OK for you to think of a domain name as being a specific machine.
The phrase "domain name" however is not the same thing as "name". Otherwise we'd just say "name". On the web, there exists the concept of a "domain" - which means a collection of machines. A domain is something like google. Domains are registered within a central and globally accessible database, organized by top level domains. Top level domains simply serve to loosely organize the web into different districts - you'll recognize the big ones - com for commercial, edu for education, gov for government domains.
Thus, the google domain is registered under the com top level domain (TLD) since it is a commercial enterprise. Combining the two, we get google.com. TLDs are not strictly enforced. Just because a domain is registered under the .com TLD doesn't mean it's "commercial". Some TLD's are regulated a bit more closely (for example, .edu and .gov) since those TLDs do indicate some degree of trust that those domains are being run by the appropriate institutions. There are many, many TLDs - some have been around for a long time (.org, .net, .biz), but within the past decade the number has exploded.
Pro Tip💡 One thing that you should understand as we discuss domains and top level domains is that the actual concept is pretty low-tech. Top Level Domains are administered by vendors. The .com TLD was originally administered by the United States Department of Defense. Responsibility for administering the .com TLD changed over to private companies, including Network Solutions and then to it's present administrator - Verisign. There are many online vendors that allow you to register your own domain under .com, but they ultimately are just middlemen, your domain is registered with Verisign. This is the same for all TLDs - different TLDs are administered by different companies. These companies maintain enormous database registries, and these registries are, by definition, publicly accessible.
The domain google.com doesn't necessarily specify a specific machine - it's a group of machines. A full domain name can build on the domain/TLD hierarchy and add any number of levels of sub domains until a specific machine referenced. A registrant of a domain is typically responsible for defining it's own listing of subdomains and machines within it's domain - typically through a name server. A name server is really just a machine that can be contacted to resolve names within a domain to specific ip addresses.
Let's say we are starting a new organization called acme. Acme will be a commercial enterprise, so we register acme.com with Verisign. As a retail customer, we would probably do this domain service provider - there are many, such as NameCheap, DreamHost, GoDaddy, etc. As a larger company, we may do this directly through Verisign or another larger player closer to the TLD. At the time the domain is registered, a specific name server will be provided. For example, if we were to register our acme.com site through NameCheap, the registration would automatically be passed to NameCheap's name servers (a primary and a backup)
dns1.registrar-servers.com
dns2.registrar-servers.com
Note, those machines have already been registered and configured, so they are accessible through the same domain name resolution process as we will discuss in a moment (this will feel a little recursive the first time you read it:)
We would also have the possibility of registering our own nameservers, if we had our own IP addresses to use (and were willing to configure and maintain our own nameservers). Maybe something like this:
primary-ns.acme.com
backup-ns.acme.com
Unless our new company called "acme" had a really large number of computers, and a lot of network administrators, we probably wouldn't manage our own nameservers - but we could.
A name server is the primary point of contact when a machine needs to resolve a more specific subdomain or actual machine name within a domain. Let's continue with our acme.com example, and suppose we had a few machines we wanted to be accessible on the internet:
www.acme.com- the machine that our web server runs onmail.acme.com- the machine our email system runs onstuff.acme.com- the machine we put our internal files on
The machine names are arbitrary, but you probably noticed that one's named www. It's not a coincidence this is named www, because that is what people traditionally have named the machine running their web site - however it doesn't need to be this way. There is nothing special about www. Incidentally, we can also just have a "default" record on our nameserver that points to a specific machine. So, we can configure our nameserver such that if someone requests the IP address of acme.com they receive the IP address of www.acme.com. This is very typical of course, we rarely ever actually type www anymore.
Pro Tip💡 In case you are wondering how a nameserver is resolved itself, it's done by contacting nameserver for the top level domain. In this case, Verisign operates a nameserver for .com, and it can be queried to obtain the IP address of registrar-servers, for example.
We've covered a lot of ground. To recap, registering a domain (ie acme) with a top level domain (ie .com) requires a name server to be listed. That nameserver has an IP address attached to it, and is publicly available. The nameserver has a list of other machines (ie www, mail, stuff), and their IP addresses.
Let's recall why we are talking about DNS in the first place. Ultimately, we want to be able write a URL with a human friendly name - http://acme.com/intro/example.html instead of http://192.45.62.156/intro/example.html. Clearly, that URL is probably going to be typed by a user, in the address bar of a web browser. So, the real question is - if the browser wants to know the IP address of www.acme.com how does it go about obtaining this information?
DNS Resolution
DNS resolution is really just a multi-step query of a giant, global, distributed look up table. A lookup table that, when flattened, contains a mapping of every single named machine to it's associated IP address.
Let's identify what is happening when we resolve www.acme.com. A web browser is just a program, and it's probably written in C or C++. One of the first things that needs to happen is that the browser code invokes an operating system API call to query the DNS system for www.acme.com. The DNS system starts with the operating system, which comes pre-configured (and via updates) with a list of IP addresses it can use to reach TLD nameservers. In this case, it will query the appropriate TLD nameserver to obtain the IP address of the acme.com nameserver (let's assume this was registered at NameCheap, so it's dns1.registrar-servers.com). This "query" is performed (usually) over UDP on port 53, although it is also commonly done over TCP. The protocol of the query is literally just the DNS protocol. The protocol is out of scope here, but it's just a set of rules to form structure questions and responses about DNS entries.
Once the operating system receives the IP address of the name server for acme.com, it does another query using the same DNS protocol to that machine (dns1.registrar-servers.com), asking it for the IP address for the www machine. Assuming all goes well, the IP address is returned, and passed back to the web browser as the return value of the API call. The web browser now has the IP address - 192.45.62.156. Note, that IP address is imagined, it's not really the IP address of www.acme.com.
Note, the web browser isn't the only program that can do this - any program can. In fact, there are command line tools available on most systems that can do it. These programs simply make API calls. If you are on a machine that has the ping command, you can type ping <server name> and see the IP address getting resolved.
> ping example.com
PING example.com (93.184.215.14): 56 data bytes
64 bytes from 93.184.215.14: icmp_seq=0 ttl=59 time=8.918 ms
You may also have a command line program named whois on your machine. You can get name server information using this. Go ahead and type whois acme.com, if you have it installed, you will see the name servers for the actual acme.com
To round things out, and to really make sure you understand how DNS resolution is achieved, here's a simple C++ program (written for MacOS) that can resolve a domain name to the associated IP address. As in the previous chapter, the goal of this code is not that you understand all the details - just that you see that it isn't magic, you just make API calls!
#include <iostream>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
#include <arpa/inet.h>
void resolve_hostname(const std::string &hostname)
{
struct addrinfo hints, *res, *p;
int status;
memset(&hints, 0, sizeof hints);
hints.ai_family = AF_UNSPEC; // AF_UNSPEC means IPv4 or IPv6
hints.ai_socktype = SOCK_STREAM; // TCP, although isn't really necessary
// Perform the DNS lookup
if ((status = getaddrinfo(hostname.c_str(), NULL, &hints, &res)) != 0)
{
std::cerr << "getaddrinfo error: " << gai_strerror(status) << std::endl;
return;
}
// The result (res) is a linked list. There may be several resolutions listed,
// most commonly because you might have both IPv4 and IPv6 addresses.
std::cout << "IP addresses for " << hostname << ":" << std::endl;
for (p = res; p != NULL; p = p->ai_next)
{
void *addr;
std::string ipstr;
if (p->ai_family == AF_INET)
{ // IPv4
struct sockaddr_in *ipv4 = (struct sockaddr_in *)p->ai_addr;
addr = &(ipv4->sin_addr);
char ip[INET_ADDRSTRLEN];
inet_ntop(p->ai_family, addr, ip, sizeof ip);
ipstr = ip;
}
else if (p->ai_family == AF_INET6)
{ // IPv6
struct sockaddr_in6 *ipv6 = (struct sockaddr_in6 *)p->ai_addr;
addr = &(ipv6->sin6_addr);
char ip[INET6_ADDRSTRLEN];
inet_ntop(p->ai_family, addr, ip, sizeof ip);
ipstr = ip;
}
else
{
continue;
}
// Here's the IP address, in this case we
// are just printing it.
std::cout << " " << ipstr << std::endl;
}
// Free the linked list
freeaddrinfo(res);
}
int main()
{
std::string hostname = "www.example.com";
resolve_hostname(hostname);
return 0;
}
If you compile this on a POSIX compliant machine (Linux, MacOS), you should get the same IP address for example.com that you got when using the ping command.
To close out the DNS discussion, what we've really done is made it possible to write URLs using people-friendly names, rather than IP addresses. Using IP addresses within a URL is perfectly valid, however we normally prefer a domain name when available.
Pro Tip💡 There's a lot more to learn about DNS, nameservers, and related technologies like CNAMEs and A records. We will discuss, much later, some of the basics of getting our web applications live on the web, by registering a domain name, and configuring it such that it is available to the public. When we do, we'll revisit DNS in more detail. There's a very detailed tutorial here if you are looking to dive deeper right away.
Noun Summary
URLs are the nouns in the HTTP protocol. They refer to resources - they may be HTML files, but they could be images, audio files, video files, PDF documents, or virtually anything else.
A URL contains a scheme, which indicates the protocol being used. In our case, the scheme will usually be http or https. The URL contains a domain name, or IP address, followed by a port number, if the port number used is not the default port number for the given scheme. After the port number, a URL can contain a path which specifically identifies the resource.
Nouns represent things, now we need to look at what we do with URLs - the verbs of HTTP.
Verbs - Requests and Responses
HTTP is a protocol for referencing and retrieving resources. In the previous section we described how resources are identified - which is of course a prerequisite for referencing and retrieving. Now let's take a look at actual retrieval.
The first thing to understand, and I'd argue that it is one of the most important and fundamental things for anyone who is learning the web to understand, is that HTTP operates on a request and response basis. ALL action begins with a request for a resource, by the client (the web browser). That request is followed by a response from the web server. That is it. Web servers do not initiate any action.
HTTP requests are just text, text that is sent over a TCP socket to a web server, from a web browser. They are formatted, they have a structure. Similarly, HTTP responses are just text too - and are sent over the same TCP socket from the web server, to the browser. The browser and client understand the format and structure of the requests and response, and behave appropriately.
Furthermore, each HTTP request and response pair is independent. That is, there is no contextual memory between requests/responses built into the HTTP protocol at all. Of course, you implicitly know that there must be some sort of contextual memory - since you know that you can do things in sequence over a series of web pages, such as build a shopping cart and check out, or login before accessing private data. This contextual memory (state) entirely managed by the web developer however, it is not part of HTTP. HTTP provides tools to support stateful interaction, but it does not do so on it's own. This is important to keep in mind as you begin.
So, what exactly is a request? A request is just that - it's a request for the server to do something to a particular resource. The server may agree, or disagree. There are only a few things that HTTP supports in terms of types or requests, although programmers can use them liberally.
The main types of requests are as follows:
GET: A request to retrieve the data associated with a resource (the resource itself). The request should be read only, meaning if multipleGETrequests are made, the same exact response should be returned, unless some other process has unfolded to change the resource.POST: A request to submit an entity (data) to the resource. This will usually change the resource in some way, or at least have some discernable side effect associated with the resource.PUT: A request to replace the current resource with another. A complete overwrite of the data, if it already exists. This is often used to create data at a given resource.PATCH: A request to modify a portion of the resource. Think of this as editing an existing resource, keeping most of the data.DELETE: A request to remove the resource.
There are a few others that are less commonly (directly) used, but are important nonetheless. We will discuss them a bit further later.
HEAD: A request to retrieve only the metadata associated with a resource. This meta-data will be exactly the same as what would have been returned with theGETrequest, but without the resource. This is useful for caching.OPTIONS: A request to learn about which verbs are supported on this resource. For example, the result may say you can't delete it.
There is a wealth of information online describing all the specifications and expectations of HTTP verbs. We will cover what we need, as we go - but you can use the MDN docs for more information.
Of the above request types, by far the vast majority of requests are GET, followed by POST. Typically, GET requests are issues automatically by the web browser whenever the user types in a URL in the address bar, clicks a link, accesses a bookmark, etc. GET requests are also used to fetch images, videos, or any other resources embedded in an HTML page (we'll see how this is done in the next chapter). POST (and GET) requests are made by web browsers when users submit forms, which you will recognize as user inputs on web pages with buttons (ie username and password, with a login button).
PUT, PATCH, DELETE are not actually used by web browsers natively - however they are used by application developers to perform other actions, initiated by client-side JavaScript. We will defer discussion of them for now, but understand that the structure of a PUT, PATCH, or DELETE request doesn't differ from GET and POST within the HTTP protocol - they are just different types of requests.
Notice also that if you are used to thinking about resources (URLS) as being files on a web server, then some of these requests make intuitive sense, and some may not. GET is probably the most intuitive, you would make this request to read the file. But what about POST? Are we actually changing a file on the server? What's the difference between POST and PATCH then? Does PUT create a new file, and DELETE remove it? The answer is "maybe" - but you might be missing the point. URLs don't necessarily point to files.
Take the following URL:
http://contactlist.com/contacts/102
This might be a URL referring to contact with ID #102. That contact might have a name, address, phone number, etc. That contact isn't a "file", its an "entity". That entity might be stored in the server's memory, or maybe in one large file, or maybe a database! It's a thing. It's a noun. You can GET it, but now maybe is starts to make more sense that you can also POST to it, PUT it, PATCH it, and DELETE it. PUT might mean replace the contact info entirely, or maybe we are attempting to create a new contact with this ID number. DELETE might remove contact 102 from our contact list. PATCH might edit, while POST might come along with some data that then gets emailed to the contact. We'll see how requests can have data send along with them in a moment.
Pro Tip💡 The request type, unto itself, is meaningless. The web server will receive the request, and decide what to do. The "web server" is just code - and you, the programmer, will write that code. Customarily, if the web server receives a GET request, it should be idempotent (it does not change the state of anything), but the server could do whatever the programmer wants it to do. It could end up deleting something. There is nothing stopping the developer from making poor choices. There is nothing inherently forcing action about HTTP. HTTP is just defining a structured way of sending requests, it isn't forcing you to take a particular action. I say all this not to encourage anyone to do unexpected things. To the contrary, I am explaining this because it's important to understand that it is up to you to design your applications to conform to the expectations of HTTP. HTTP has stood the test of time, for nearly 40 years, through all the changes we've seen. It is wise to follow it's intended purpose, you will be rewarded - but keep in mind, you must actually do the work, nothings happening for you!
Making a Request
In the last chapter, we discussed domain name resolution. We know that given a URL, one way or another, we can obtain the following:
- The IP address of the target machine
- The port number to send data to
- The protocol we expect to use.
For example, if we have the following URL:
http://example.com/index.html
We know that example.com can be resolve to an IP address (at the time of this writing, it's 93.184.215.14). We know, since the protocol is http, the port is 80 since it's not specified otherwise. Thinking back to the echo server example, we now have enough information to open a socket using the TCP protocol to this server - all we needed was the address and port number.
Pro Tip💡 TCP is the transport protocol used for HTTP (and HTTPS). It doesn't make any sense not to use it, in the vast majority of cases. There may be some niche use cases where UDP is used in an unconventional situation, but it's rare enough for us to completely ignore for the remainder of this book.
In the echo server example, we opened a socket to the echo server (from the client) and sent over some text. The echo server responded by sending back the same text, capitalized. This was a request/response pair - but there was no structure to the message. This is where things start to diverge, and we see that HTTP provides structure, or almost a language to facilitate hypertext actions.
The most basic request contains only 4 things:
- The verb
- The path of the resource
- The version of HTTP the client is speaking
- The host the request is intended for.
The verb should be self explanatory - it's GET, POST, PUT, etc. The path of the resource is the path part of the URL. For example, if we are requesting http://example.com/foo/bar, the path is /foo/bar. The path identifies the resource on the given machine.
HTTP is just a text format, so given the first to things, we'd format the text request as
GET /index.html
This text would be sent straight to the webserver, just like the echo client sent straight text to the echo server. In this case however, the server would parse the text, and decide how to handle it.
Unfortunately, that's not enough. We have two more requirements - version and host.
First, the version (#3) - HTTP just like anything else in computer science, changes. It hasn't changed a lot though - it's actually remarkably stable. Version 0.9 was the first "official" version, and it just let you GET a resource. No other verb was present. Version 1.0 (mid 1990's) added things like headers (we'll see them in a bit), and by the late 1990's HTTP Version 1.1 was standardized. HTTP Version 1.1 is essentially still the defacto standard used - some 35 years later. In 2015 HTTP Version 2.0 was standardized. HTTP Version 2.0 is widely supported and used, however it's somewhat transparent to the web developer - as the major change was that it is a binary protocol with the ability to multiplex (have multiple simultaneous requests over the same socket) and enhanced compression. It does not make any changes to the actual content of the HTTP request (or response).
Suffice to say, in this book we'll use Version 1.1, since it's the latest text-based version. You wouldn't want to read HTTP in binary. Since ultimately we won't be writing our own HTTP beyond this chapter, instead letting libraries do it for us, the switch to Version 2.0 won't change anything for us.
The version is the third entry on the first line, which is referred to as the start line:
GET /index.html HTTP/1.1
Finally, we have #4 - the "host the request is intended for". Technically this is required, but in most cases it is. It is not at all uncommon for the same physical machine to host multiple "web sites". For example, you might have two domain names within your domain:
www.acme.com
private.acme.com
The www site might be the public facing website, while private might be a web portal used by employees, requiring a login. They are two separate domain names - however, to save costs, we want to have both sites served by the same physical machine. This might make a lot of sense actually, since it's unlikely the private portal has enough traffic to warrant it's own machine, and the two sites probably share a lot of the same data.
Since both domain names resolve to the same IP address, two clients sending requests to these sites would send their HTTP to the same web server. The web server would have no way of knowing which domain the client was looking for.
To make this clear, the following are two valid web addresses, and presumably two different resources.
www.acme.com/info.html
private.acme.com/info.html
The path is the same, but they are different web sites, from the perspective of the user. To help the web server understand which site the request if for, we add our first HTTP header, the Host header to the GET request.
GET /index.html HTTP/1.1
Host: example.com
From the acme examples above, we can now see why the requests would be different. Both of the following request go to the same web server, but the web server can see that one is asking for /info.html from www.acme.com and the other from private.acme.com.
GET /info.html HTTP/1.1
Host: www.acme.com
GET /info.html HTTP/1.1
Host: private.acme.com
Of course, it's up to the web server to be smart enough to differentiate the two requests and return the right resource!
Making a request yourself
We could take the echo client code we wrote in Chapter 2 and actually modify it to use port 80, and connect to example.com. We could then literally send two lines of text to it, conforming to the HTTP specifications, and get a response. It's a bit tedious though to keep doing this in C++ code.
We can quickly see how this works by using a common command line tool that is a lot like the echo client we wrote before - telnet. Telnet has been around for 50 years, and is available on most platforms. It lets you specify a host and TCP socket, and it opens a socket to that server. It then accepts anything you type at the command line, and shoots it across the socket. The response from the server is printed to the command line.
Go ahead and try it, if you can install telnet on your machine:
> telnet example.com 80
It will connect, and then sit and wait for you to type something.
Type GET / HTTP/1.1 and then enter. Nothing will come back, because the web server is waiting for more before responding. Type Host: example.com, and again - nothing will come back just yet.
The last requirement of an HTTP request is a blank line. This tells the server that you are done with the request. It's a really low tech delimiter!
Just hit enter again, and you'll see the full HTTP response from example.com come back, and print out. It will look something like this:
HTTP/1.1 200 OK
Accept-Ranges: bytes
Age: 86286
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Fri, 13 Sep 2024 18:40:40 GMT
Etag: "3147526947+gzip"
Expires: Fri, 20 Sep 2024 18:40:40 GMT
Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT
Server: ECAcc (nyd/D144)
Vary: Accept-Encoding
X-Cache: HIT
Content-Length: 1256
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
What we have above is a full HTTP response. Pure text. Go ahead and open a web browser now, and type example.com into the address bar. You'll see something like this:

The web browser did the same thing as telnet did, but in a nicer way. It took what you typed in the address bar, example.com, and formed an HTTP GET request from it, pretty similar to what you entered into telnet. When it received the response, instead of showing you the pure text (which includes HTTP details we will learn about in a moment), it actually rendered the HTML that was included in the response.
Congratulations, you've demystified a lot of what you've been doing with a web browser most of your life already. The browser is just sending well formatted text to a server, and the server is responding. You've seen the raw text now - no magic.
Requests in HTTP really aren't a whole lot more complicated than what we've seen. In the real world, the only additions we generally have are (1) more headers, (2) request query strings, and (3) request body data. Let's take a look at those now:
Adjectives?
We've been building this analogy, of describing HTTP in terms of nouns (URLs) and verbs (request types). The analogy can go a little further, although it might be a perfect grammatical match. Adjectives are used to describe things - and in HTTP, we can use additional mechanisms to (1) describe the things we are requesting, (2) describe the details and parameters of the request, and (3) supply additional data along with the request. We do that using headers, query strings, and the request body.
Request Headers
We already saw one request header, the host header. Request headers are simply name / value pairs, separated by a colon, one pair on each line, right after the first line of an HTTP request. Recall, an HTTP request is in fact delimited by new lines, the first line is the start line, and then each line after that is a request header pair. The end of the request header pairs is denoted by a blank line, which is why we needed to press enter one extra time when interacting with example.com using telnet!
GET /info.html HTTP/1.1
Host: www.acme.com
another: header value
last: header value
<blank line>
Request headers are used to apply additional meta data to the HTTP request itself. The are many valid request headers, and we don't need to exhaustively enumerate them here. Let's cover a few, so you understand what they could be used for, and then we'll rely on other reference material for the rest.
Common Request Headers
- Host - the only required header for a valid HTTP request, used to support virtual hosts.
- User-Agent - a plain text string identifying the browser type.
- Accept - a list of file types the browser knows how to handle.
- Accept-Language - a list of natural languages the user would like responses to be written in (the HTML).
- Accept-Encoding - a list of compression formats the browser can use, if the web server wants to use compression.
- Connection - indicates whether the TCP connection should remain open after the response is sent (
Keep-aliveorClose) - Keep-Alive - indicates the number of seconds to keep the connection open, after the response is sent. This only makes sense when
Connectionis set toKeep-Alive - Content-Type - used for requests or responses, indicating what type of data is being sent. Some requests can carry with them additional data (typically POST, PATCH, PUT), and this helps the server understand what format the data is being transmitted in.
- Content-Length - the additional data being sent with the request (or the response) has a length, in bytes. In order for the server (or client, when dealing with responses) to be able to handle the incoming data, it's useful to know how long it is.
Content-Lengthwill represent the number of bytes that are being sent. Note, as we will se, the content in question is sent over the socket after the headers. - Referrer - the URL the user is currently viewing, when the request is made. Think of this as being set to the url of the web page that the user clicked a link on. Clicking the link results in a new HTTP request to be sent, for that page. The new request will have the original page as the
Referrer. This is how a lot of internet tracking works, when you arrive at a sight by clicking a link, that web site will know which web site (URL) led you to it.
It's worth taking the time to point out, headers are suggestions to the web server. Your HTTP request might provide a list of natural languages it would like the response in, but that certainly doesn't mean the web server is going to deliver the response in that language! Some web applications do have language options - but the vast majority do not. If the HTML on the server is written in Spanish, it doesn't matter what that your HTTP request uses Accept-Language to ask for Japanese. It's coming in Spanish!
Note that as an end user, you aren't all that used to thinking about these request headers. Your browser fills them in for you. Some may be based on user preferences (for example, the language you speak). Others are default values from your browser - like User-Agent. If you are using a Firefox web browser, the User-Agent string is set to Mozilla/5.0 (platform; rv:geckoversion) Gecko/geckotrail Firefox/firefoxversion, where geckoversion and firefox version depend on your browser install.
It is important to remember that the web server cannot trust anything sent to it! For example, while Firefox sends a User-Agent string identifying the HTTP request as coming from Firefox, I could also write a telnet clone that added the very same User-Agent string to each request. The web server would have no idea that my own little program was not, in fact, Firefox! In the next section, we'll see how these headers are send/received in code - and it will be even more obvious.
A web server CANNOT accept anything written in an HTTP request as truth, it's just plain text, and it could be sent by anyone, with any program, from any place on the planet!
There are many, many headers. Check out the MDN for an exhaustive list. We'll come back to some of these as we progress, when there's more context to discuss around them.
Request Query Strings
Type https://www.google.com/ into your web browser. Not really surprising - you'll see google's home page, with an input box for your search term. That page is loaded as a result of your web browser generating an HTTP GET message, that has at a minimum the following:
GET / HTTP/1.1
host: www.google.com
Now, close the browser and reopen it. Type the following instead: http://www.google.com?q=cats.
You have the same page, but now notice that the contents of the search box, in the google.com home page, is filled out. It's filled out with what you added - q=cats results in "cats" being in the search box.
The web browser sent (roughly) the following message:
GET /?q=cats HTTP/1.1
host: www.google.com
Both requests are still identifying the / (root) home page on google.com as the page being loaded. However, the page is loaded/rendered differently when we include the new q=cats suffix.
The ? at the end of the string you typed marks the end of the path in the URL, and the beginning of the query string. The query string is a sequence of name / value pairs, with name/pair separated by the = sign, and pairs separated by the ampersand &. URLS cannot have spaces in them, and there are some other special characters that cannot be used either. The query string must be encoded to be a valid part of a URL, so if we were thinking of searching for "big cats", we'd need to use the query string q=big%20cats, for example. Most browses will accept and display spaces and other common characters, and seamlessly encode the URL before sending over the network.
As you might imagine, query strings aren't terribly difficult to parse (aside from the encoding rules, to an extent). Query strings are useful because they allow the user to specify an arbitrary number of name value pairs that the web server can use to satisfy the request. Query strings have a maximum length, which generally varies from server to server. The maximum length is usually around 2000 characters, but it can be as low as 256 characters. If you exceed the maximum length, the server may return an error. Web browsers also place a limit on the length of a URL in total, including the query string.
Query strings can appear in GET requests (most often), but they can appear in all the rest too - POST, PATCH, PUT, DELETE. They are supposed to be used as modifiers to the requested resource. An important aspect of query strings is that they are visible to the end user. They appear in the address bar of the web browser, and they are often used to pass information.
Go ahead and click "search" on google, with "big cats" in the search bar. Yes, you get search results, but also take a look at the address bar. The uRL will likely look something like this:
https://www.google.com/search?q=big+cats&source=somereallylongtrackingstring&oq=big+cats&gs_lp=somereallylongtrackingstring
There's probably more tracking strings in there, google works hard to hold on to some data about you and your browser. But let's keep focused on the search itself. When you clicked the "Search Google" button, you were submitting an HTML form (more on this later). The browser was instructed by the HTML to issue a new HTTP request, this time, a GET request to www.google.com/search. Note the path, /search. search certainly doesn't correspond to a static HTML page somewhere on google's servers, it's handled by code - and that code examines the value of the query string to know what you are looking for. In this case, the q parameter is used, and search results for "big cats" are returned.
The URL above, with the /search path and q is shareable and bookmarkable. You can copy and paste that URL into an email, and the recipient will see the same search results that you did. This is a powerful feature of the web, and it's all thanks to the query string. Whenever we want to issue a request to a particular URL, but we want to specify additional information, refinement, or clarification - we can use query strings. Keep in mind, the server needs to expect them, and be willing to use them, you can't just invent them on your own from the browser :).
Once you see them, you see them everywhere. Keep an eye on your browser as you use the web, and you'll see query parameters being used all the time, they have thousands of uses.
One of the more intimidating things about the web is that sometimes it can feel like there are a lot of ways of doing things, and that certain aspects of the technologies end up getting used in many different ways. While that's true (it gets easier with practice), there is usually some sort of rhyme and reason behind choices.
Query strings are best used when you are retrieving a resource (ie. GET), and are best used for specifying some sort of variation of the resource. This might be any of the following:
- the search term to use when generating search listings
- the starting and destination addresses in a door-to-door mapping site
- page numbers, limits per page, and other filters on product search pages
- ... and much more
Query strings are great when the query string is a meaningful part of what you might want to copy, save, or later visit. Query strings are part of the URL, and thus are saved in browser history.
Request Body
Think of the last time you logged into a web site. You entered your username or email address, along with your password. Then you clicked "Login" or "Sign in". This isn't much different than typing "big cats" into Google's search bar, and pressing "Search". Both pages use an HTML form (we'll see it in a while). However, something is very different. Unlike the search results page on Google, after you click the button and login, your username and password are not shown in the address bar. The username and password were sent along with the request, but they were not sent as query parameters. Instead, they were sent as part of the request body.
Before moving forward, it's worth nothing something really important. Just because the request body doesn't show up in the address bar, the data sent to the web server as part of the request body is not private and is not secure. Of course, it's better to use the request body rather than query parameters for sensitive information, it would be embarrassing to have this information right out in the open on the screen, for all to see, copy, and view in browser history.
https://embarassment.com/login?username=sfrees&password=broken
However, do not make the mistake of thinking a user name and password are safe from prying eyes just because you put it in a request body instead. Unless you are using TLS/HTTP, which encrypts the HTTP request itself, then anyone can intercept your HTTP request and can absolutely read the request body! It's still sent as plain text - it's just slightly more discrete.
Now let's get back to the request body. An HTTP request contains a start line and then one (the host) or more HTTP request headers, as described above. The request can have any number of headers, each on their own line. A blank line indicates the end of the HTTP request headers. After the blank line, however, additional content can be sent. This additional content is the request's body.
In order for an HTTP request to have a body, it must have Content-Length as one of it's headers. In nearly all cases, it also must have Content-Type as one of it's headers as well. This allows the web server to read the request headers, understand what is coming, and then to read the request body itself.
Not all HTTP verbs may have request bodies. When using a request body, you are limited to POST, PATCH, and PUT. More on why that is in a moment.
Here's an example of an HTTP POST message that submits some text to a URL on example.com
POST /test HTTP/1.1
Host: example.com
Content-Length: 26
Content-Type: text/plain
Hello World - this is fun!
Pro Tip💡 You might have noticed that a lot of the urls we are starting to use do not have .html extensions. It's helpful to start moving away from the notion of urls ending with .html - they usually do not. The path part of the URL ordinarily maps to code, that generates a response (usually HTML). Situations where URLS map directly to plain old HTML files on the server are rare, and the exception.
In the request above, the Content-Type indicates that the request body is simply plain text, and the Content-Length header tells the receiver to expect 20 bytes. If you think back to the Echo Server we wrote in chapter 2, you can imagine how a program (the web server) may read each line of the HTTP request - start line, then the headers - and then use that information to allocate enough space to read the rest of the request body.
Reading 20 bytes is one thing, but understanding it is another. In the first example above, text/plain indicates that there really isn't much to parse - and that they bytes should just be interpreted as normal ASCII code characters. text/plain is a MIME type - one of many internet standard format codes. We'll discuss more when we describe responses, but requests can have several Content-Type values that are pretty meaningful.
Let's return to that hypothetical login situation. We will learn about HTML forms in a future chapter, but for now let's just assume they allow use to specify a name for each input field, and then whatever the user types in the text box is the value. Those name value pairs can be used in to build a query string, but they can also be part of the request body instead.
Here's an HTTP post that includes form data - name value pairs formatted just like they were when part of the query string, but now they are part of the request body.
POST /login HTTP/1.1
Host: example.com
Content-Length: 31
Content-Type: application/x-www-form-urlencoded
username=sfrees&password=broken
Here, the request body is ASCII text, but the header is indicating to the web server that it is actually encoded as name value pairs, using the = and & delimiters. The server can read the request body (all 31 bytes of it) and parse it - just like it would parse the same data if it were at the end of a url as a query string.
Request bodies can be relatively short, where form data like that shown above is being sent with the request. However, request bodies can also be very large. They are used to upload lots of text and to upload files of arbitrary length. Web server will usually impose some limit on the length of a request body, but it's on the order of 10's of megabytes, or possibly far far larger.
Query Strings or Request Body?
In most cases, whether to use query string or request body to add data to a request is fairly straightforward conceptually. If you are sending modifiers, then those are usually done as query strings. Again, things like search terms, page numbers, page limits, etc. If you are sending what you would consider data, especially if that data is meant to persist somewhere, then you are probably better off using request body. Here's a further breakdown:
- Use Query String if:
- Data is clearly name value pairs
- There is a fairly limited number of name value pairs, and they are fairly short (under 2000 character total)
- The name/value pairs aren't sensitive at all, you are OK with them being copy and pasted by users, and showing up in bookmarks and browser history.
- Use Request Body if:
- Data is meant to change the state of some information store, or the state of the application itself. This includes data that will be stored to a database, the session (we'll see this later), login data, etc.
- The data is large (anything over a couple of thousand characters)
- The data is sensitive (remember, the request body isn't secure either, but it's better than having it in the address bar!)
Data size and sensitivity is pretty straightforward. The idea that the data, coming along with a request is thought of as data rather than a modifier is a little more subtle. It's a bit of an art form, but it lines up with why we use different HTTP verbs too. It might help to see it in that context:
- HTTP GET: Does not have a request body. Query string is the only way to transmit data with the request. GET is, by definition, supposed to be a read-only operation - the state of the server should not change as a result of the GET request.
- HTTP POST: Can have request body, and query string. Recall, POST is used to submit an entity (data) to the resource. The data being submitted, which is usually thought of as something that will be persisted, or have some sort of side effect, usually is sent in the request body. Parameters that may effect which resource is being affected, or how, might make use of query string.
- HTTP PUT: Usually will just use request body - which includes the data to create or overwrite the resource. Again, it's possible that a query string can be used, in conjunction, to further refine what type of entity is being created or overwritten - but the data belonging to the entity will be sent as a request body.
- HTTP PATCH: Same as PUT, in that the entity data being modified is usually best sent as a request body.
- HTTP DELETE: There is never a request body for a DELETE request, as no data is being sent - only removed. It is possible that query parameters may serve as ways to specify options for deletion (aks soft delete, cascading delete, etc).
We've already seen an HTTP response a few times now. Let's dive into what a well formed HTTP response looks like now.
HTTP Responses
When a web server receives a request, it has complete control over how to respond. One of the first things that it will do is decide between some categories of ways to respond. There are 4 main types of responses:
- Everything is ok, so I'll perform the request
- The request is fine, but you (the client) should request something else instead
- The request is invalid, you (the client) have made an error, and there will be no response.
- The request was possibly valid, but the server has encountered an error and no response is available.
Response types 1, 3, and 4 probably make sense. Response 2 probably seems a bit odd, but it's useful.
Pro Tip💡 A reminder: Saying "it has complete control" is inaccurate. YOU, the web developer coding the logic on the web server, have complete control!
In it's most simple form, an HTTP response need only respond with a single line of text - which includes the HTTP version, the response code (derived from the type above), and a text description of the response code.
Here's a typical response for when things go well:
HTTP/1.1 200 OK
Here's a response for when things go badly, and the server encounters an error.
HTTP/1.1 500 Internal Server Error
Clearly, we are using HTTP version 1.1. Notice the codes 200 and 500. Those are response codes, and there are a bunch of them worth remembering.
200- OK. Use this for most successfully and normal responses.301- Moved permanently. Use this when the resource should no longer be accessed at the requested location, but instead a new location is provided. We'll see in a moment how the new resource location would be specified.307- Moved temporarily. Use this when you want the client to make the request somewhere else instead, this time - but that the original location was valid generally. We'll see this used soon.401- Unauthorized. This is named poorly, what it really means is unauthenticated. It means that the resource if valid, but you need to authenticate yourself. We'll see more on the difference between authentication and authorization later, but they aren't exactly the same thing.403- Forbidden. This means you don't have access to the resource. This is the closest match to unauthorized, as it's commonly used.401means the server doesn't know who you are,403means the server knows who you are, and you aren't allowed to access the resource.404- Not Found. The resource doesn't exist.500- Internal Server Error. This is used when some sort of unhandled error occurs. Generally its a bad idea to return details of what went wrong, since it's publicly advertising aspects of your code. This is normally used when the web server code throws an exception, or some other sort of catastrophic error occurs.501- Not Implemented. Use this when the resource request is planned, but you haven't gotten to implement it yet.
There are a lot more. It's certainly worth keeping a reference handy. Responding with the best response codes for the situation the web server finds is somewhat of an art form, but is well worth the effort.
Pro Tip💡 The text after the status code in the HTTP response code is a bit of an anomaly. Strictly speaking, it should be the same text that is used to describe the status code in the official specifications. In practice, developers often override this, and include other text - perhaps more accurately describing the result. This can be potentially unwise, since it's possible a client could use the response text in some way, and behave unexpectedly. Web browsers will generally display the response code string to the user, as part of a generically formatted HTML page (especially for 400 and 500 level codes), and particularly when no body (HTML) portion is included in the response.
We already saw a more full response earlier in this section, when reviewing the HTTP request/response from example.com. We saw that the following request:
GET /index.html HTTP/1.1
Host: example.com
... resulted in the web server responding with the following response (truncated to save page space):
HTTP/1.1 200 OK
Accept-Ranges: bytes
Age: 86286
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Fri, 13 Sep 2024 18:40:40 GMT
Etag: "3147526947+gzip"
Expires: Fri, 20 Sep 2024 18:40:40 GMT
Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT
Server: ECAcc (nyd/D144)
Vary: Accept-Encoding
X-Cache: HIT
Content-Length: 1256
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
... more HTML
At this point, some of this response may be feeling similar to what we saw with requests. The status line (the first line) is indicating the version and result code. The next 12 lines are response headers, formatted the same way they were in requests. Then there is a blank line, and then the response body.
Headers
Response headers are used by the web server to describe the response to the client. Remember, the client (the web browser) needs to read the response from a socket. The response is plain text, and the client must read the headers before the response body (assuming there is a response body). With this in mind, some of the response headers you see above should make sense:
Accept-Ranges: indicates if the server supports range requests, which are requests that ask for only parts of the document. This isn't commonly used, but you could imagine this would be helpful when requesting things like videos, where you only want a certain range (time period) returned.Vary: Usually used in caching, to decide how to cache the response.Age: Amount of time the response data was in the servers or proxy cache.Cache-Control: Advises the browser how long to cache the response (meaning, the browser should skip issuing a new request for this resource within the given time frame) Responses may contain binary data, and that data could be in the form of a file - with various extensions. Here, the more exhaustive list of MIME types fits our use case more, since the browser needs to be able to handle many more types of responses.Date: Primarily useful for caching on the client side, it's just saying what the date of the response was.Etag: This is a lot like a checksum, it's a hash of the response. This can be used, in conjunction with theHEADrequest to allow the client to determine if it's worth requesting a resource that was recently requested and cached. If the Etags match (recall,HEADreturns only the headers, not the entire content), then there is no reason to issue a full request.Expires: Advises the browser not to cache the request beyond a certain time.Last-Modified: Can eb useful for client-side browser cachingX-Cache: Headers starting with theX-prefix are not standard headers, they are user (in this case the server) defined. In this case, it likely means the server responded to the request with cached data.Content-Type: Serves the same purpose as with requests - tells the client what kind of data is being sent, so it can be effectively handled. - -Content-Length: The number of bytes in the response body!Server: Sort of likeUser-Agent, but for servers. This identifies the server software. In most cases, this is not recommended, since it let's would-be attackers know more than they need to know - and the more they know, the easier it is to find exploits. There are very few logical reasons a browser needs to know this information.
There are a lot of request and response headers. The MDN has a fantastic list, we don't need to enumerate them all. For now, there are a few takeaways though:
- Response headers often describing caching. Caching is a critical aspect of the web. Caching will occur on the server side, and headers will be used to describe that (
Vary,Age,Date,X-Cache, etc). Caching also occurs on the browser side, and often the server will assist in this process - including headers such asExpires,Etag,CacheControlto help guide the browser. - Response headers, just like request headers, will describe the body of the response. In particular, the content type, encoding, and length. This information is critical to be able to read the appropriate data from the socket, parse it, and process it.
MIME Types
Just like with request bodies, MIME types play a pivotal role in describing response bodies. For responses that are delivering a resource, the resource will be delivered via the response body. For 300 (redirect) responses, 400 (client error) responses, and 500 (server error) responses, the response body may or may not be used, and is often ignored by the browser. If you've ever seen a fancy web page render that says "Not found", but with a lot of cute graphics, it's because the 404 response has a response body, and the browser rendered it.
A response body is typically going to contain data that is either meant for the browser to render directly (this include plain text, HTML, CSS, JavaScript code, images, audio, video), or files that the browser may either attempt to render (CSV data, JSON data, PDF documents) or use the underlying operating system to launch a better program to open (a Microsoft Word document, for example). All of this is of course determined by the MIME type.
It's important to understand that for every response, there is one request - and for every request there is one response. As we will see, often a request for an HTML page will result in HTML being loaded in the browser, and then for that HTML to contain links to other resources. Many times, those resources are requested right away, in sequence. For example, after loading HTML with references to images, the browser will initiate new requests for each image, at the URL listed in the HTML. We'll dive into to this in more depth later - but for now it's important to remember that there is not mixed responses.
Response Body
There response body itself is simply text, or encoded text. Depending on the MIME type, the data might be URL encoded binary data (essentially, data that appears to be gibberish), or it could be perfectly readable text. The text might be structured (CSV, JSON, HTML, JavaScript code, CSS), or it might be unstructured (plain text). No matter what, the response body always follows a blank line in the HTTP response message, which in turn follows the last HTTP response header.
No matter how large the response body is, it's still part of the HTTP response. This means that just like a short little HTML page being returned by example.com, an HTTP request that is generated for a multi-gigabyte mpeg-4 video is going to be returned as a standard HTTP response. The difference is that the Content-Type will indicate that it's a video (maybe /video/mp4), and the video data will be very long, using binary encoded text data.
Redirects
We discussed 400 and 500 error codes, and they are fairly self explanatory. A response within those ranges are telling the browser (and the user) that the request failed. The actual code, and potentially the response body, will tell them a bit more about why - but the bottom line is that the request itself failed.
A 200 response code, and all of it's variants, is also fairly self explanatory. The resource was returned, and in most cases, the browser will simply render it.
The 300 level codes are a bit more difficult to succinctly explain. 300 level codes indicate that the resource the client has requested (the URL) exists, but exists elsewhere. These response codes are telling the web browser that the response was not necessarily an error, but the web server cannot fulfill the request. Instead, the web server is advising the web browser to make the request to some other location (URL).
Let's start with a simple (and probably the original) use case: someone decided that a page on the website should move to another location:
- Original url: http://www.example.com/a/b/c/data.html
- New url: http://www.example.com/other/data.html
Suppose someone has bookmarked the original URL, and so they make a request to the /a/b/c/data.html path. The web server, of course, could simply return a 404 - not found. However, in order to help, it instead can return a 301 status code - indicating that the resource has moved permanently.
On it's own, this isn't particularly useful. Where this becomes more powerful is when the 301 response code is coupled with the Location response header, which is used to indicate the new location.
HTTP/1.1 301 MOVED PERMANENTLY
Location: http://www.example.com/other/data.html
Now, the web browser may elect to actually process this response and issue a NEW request to the new URL, /other/data.html. Most web browsers will do this. It's called "following the redirect", and it happens automatically. You will see the address bar change, with the new address displaying.
The situation described above is easiest to describe, but it isn't the most common type of redirect response used. The 307 Temporary Redirect response is actually the redirect that is most frequently used on the web. This is because there are many cases where it's not that the resource has moved, but that the web server wants the web browser to issue a new request following the first.
A typical sequence that utilizes the 307 code is for logging in. Typically, the browser will send a request to a url list /login, as a POST request. The login logic will decide if the user can log in (their passwords match, etc), and then the user will likely be presented with a page based on their role. They might see a detailed dashboard, perhaps if they are a site administrator. They might see a more limited screen if they are a normal user. The point is, depending on who they are, and what they do, they may have a different "home" page after logging in.
At first, you might think that we'd just have one set of code in charge of rendering /home, which takes into account all that logic. But in fact, it's usually better (and easier) to create multiple pages for the different types of users. Maybe something like /admin/home and /user/home. Those URLs can simply focus on rendering the right content.
The trick is, how do we response to the POST request to /login, but at the same time somehow navigate the user (after login) to the right home page? We use a 307!
- If the POST to
/loginfailed (username invalid, password doesn't match), we could response with a307withLocationset to/loginagain - so they could repeat the login attempt. - If the POST to
/loginsucceeded, the web server would presumably make note that the user was logged in (we'll see how this is done later), and *redirect the user to either/admin/homeor/user/homeusing theLocationheader.
In all three cases, the browser will automatically request the url specified in the Location header.
The next time you log in to a website, watch the address bar! In almost every case, you'll notice that it switches to something else after you've logged in. Sometimes there are even multiple redirects!
HTTP Implementation - The Hard Way
In the previous sections, we used some text-based programs like telnet to simulate what a web browser does - constructing a text HTTP request and sending it to a web server. We saw first hand that web servers do not really know (or care to know) what program generates an HTTP request. If a web server receives a valid HTTP request, it sends back a valid HTTP response!
It's also useful for you to start to understand the server side a bit more. Recall back in Chapter 2, when we wrote an Echo client and server - with just plain old JavaScript and sockets (we started with C++). Below is an adaptation (actually, a simplification) of a TCP server written in Node.js
const net = require('net');
const on_socket_connect = (socket) => {
socket.on('data', (data) => {
const request = data.toString();
console.log(request);
})
}
const server = net.createServer(on_socket_connect);
server.listen(8080, 'localhost');
Remember, until we start really learning JavaScript, you should try not to get too caught up in syntax. We will cover it all - right now code examples are just to illustrate concepts.
The code above creates a TCP server using Node.js's built in net library. The server object is constructed by calling the createServer function in the net library. The createServer function accepts one parameter - a function callback, which will be called whenever a client connects to the server. Once the server object is created, it is set to the listening state, on port 8080, bound to the localhost.
The interesting stuff is happening in the on_socket_connect callback function. When it is called (by the net library's server code), a connection has been established with a TCP client. That connection is represented by the the socket parameter. on_socket_connect now registers another callback - this time an anonymous function. We'll cover these later in more depth, but for now think about how in most languages you can have literal numbers (ie 5) and named variables that hold numbers. Well, in JavaScript, functions are data, and thus we can have literal functions (without names) and named variables that represent functions. on_socket_connect is a named function, but so it the function that we create and set as the second parameter to the socket.on function in the code above. The socket.on function is a generic event registration function. The first parameter is the type of event we are registering a function for - in this case, we are interested in defining a function to be called whenever data is received from the client. The second parameter is the function itself, which we want the socket to call when data is received. The function accepts a single argument (data), converts it to a standard string, and prints it to the console.
You are strongly encouraged to take this code and run it on your machine. If you have it running, you can launch a web browser (any web browser will do!), and enter the following into the address bar: http://localhost:8080.
Observer what happens. The web browser is the TCP client! It generates an connects to the server, over port 8080. It sends an HTTP request message, and the server successfully receives it and prints it out! You will see something like this print to the server's console:
GET / HTTP/1.1
Host: localhost:8080
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:131.0) Gecko/20100101 Firefox/131.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/png,image/svg+xml,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br, zstd
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Priority: u=0, i
Depending on yoru web browser, you might have something slightly different, but chances are your web browser generated and HTTP request that looks a lot like the above. Your server received it over the socket!
Also take a look at the web browser. It's likely that you'll notice it still needs to receive a response - it's still waiting. You've seen this before, whenever your browser is having trouble connecting - here's a screenshot of Firefox:
So, why is your web browser hanging? It's really pretty simple - it expects our web server to respond! Our web server printed to the console, but it didn't send anything back to the client - it left the client hanging!.
Let's follow each request we receive with the simplest HTTP response we could possibly return - OK, with no content.
const net = require('net');
const on_socket_connect = (socket) => {
socket.on('data', (data) => {
const request = data.toString();
console.log(request);
// Note the extra blank line, to tell the client there are no more headers
const response =
'HTTP/1.1 200 OK\n' +
'Content-Length: 0\n' +
'\n';
socket.write(response);
})
}
const server = net.createServer(on_socket_connect);
server.listen(8080, 'localhost');
If we re-launch the server (when we do so, you might notice the browser that was hanging for a response gives up, since the socket is disconnected), and reload the web browser - we'll see something. A blank web browser page!.
Before we go much further, let's discuss web developer tools. As a web developer, it's critical that you can debug your programs. When writing your own server code (as we are right now), it's easy to print to the server's console, or even run a proper debugger and inspect the operation of the server code. Sometimes, however, you need to see what the browser receives in order to better debug your code. In this case, you'd be forgiven to wonder why the browser is showing a blank screen (maybe you understand why already, if so - great!). Our server sent the 200 reponse, so what gives?
In [Google Chrome], Chromium, Firefox, and other major browsers, you have the ability to peer into the internals of the web browser to inspect lots of things that ordinary users have no interest in. One of these things is the actual network traffic - the actual HTTP requests. I recommend that you get very familiar with the web developer tools that come with your favorite web browser for software development. Note, Safari and Microsof Edge (at least at the time of this writing) do not offer the same level of tooling - for development, I recommend using Firefox or a Chromium-based browser.
Here's what you will see when accessing the Network tab in Firefox's dev tools when making the request:
We can clearly see, the browser did receive our response - a 200 status code, with OK as the message. The Content-Length is 0. Well, maybe now that jogs our memory - the browser renders content, not the actual HTTP response. We can see the HTTP response in dev tools, but without sending any content (response body), the browser isn't going to render anything!
Let's send something, shall we? We can create some text, and add it to the response body, being careful to adjust the Content-Length header accordingly. Since it's just plain text, let's also go ahead and set the Content-Type to the correct MIME extension.
socket.on('data', (data) => {
const request = data.toString();
console.log(request);
const text = 'Hello, World!';
const response =
'HTTP/1.1 200 OK\n' +
'Content-Type: text/plain\n' +
'Content-Length: ' + text.length + '\n' +
'\n' +
text + '\n';
socket.write(response);
})
Now when we load the browser, we see our Hello World text. It's also clear in the dev tools that the browser received the HTTP response we sent, in full.
Plain text is pretty boring. Browsers can render all sorts of content, as we know. Let's instead send some HTML:
const on_socket_connect = (socket) => {
socket.on('data', (data) => {
const request = data.toString();
console.log(request);
const html = `
<!DOCTYPE html>
<html>
<head>
<title>Sample Page</title>
</head>
<body>
<h1>Hello World</h1>
<p>This is fun!</p>
</body>
</html>
`
const response =
'HTTP/1.1 200 OK\n' +
'Content-Type: text/html\n' +
'Content-Length: ' + html.length + '\n' +
'\n' +
html + '\n';
socket.write(response);
})
}
We see that our HTML that we generated using just a simple little program renders just like any other HTML we see on the web:
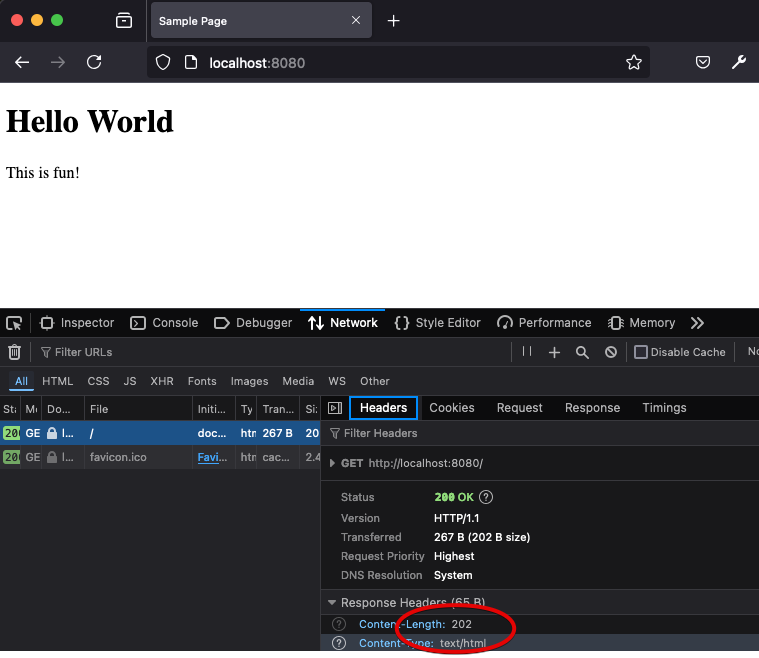
Responding to Requests
You might have noticed something odd in the web developer tools screenshots above. In each, there are actually two requests - one for /, which is the request directly caused by typing http://localhost:8080 in the address bar, and another for /favicon.ico. As a matter of convention, web browsers always issue a request to any web site it is loading resources from to favicon.ico. You can try it out, visit any other site, with web developer tools open - you'll see the request (be prepared, on a modern web site, one site visit triggers many requests to sift through).
A favicon is the graphic/logo you see at the top of the browser tab. It's usually the same across the entire web site you are visiting. Your browser is getting them automatically for you, and using whatever is returned to it.
You can actually just enter the following into the address bar to laod the favicon directly for google: https://google.com/favicon.ico.
So, that's why you see the two requests - but interestingly, our "Sample Page" doesn't have a logo. We're not going to create one right now, but you might be curious - why is our server returning 200 to the /favicon.ico request then?
Why does our server do the things that it does? Because we wrote it that way! Our server returns 200, along with the same HTML for every request it receives! In fact, if you look at the console output of the server, every time you load the page in the browser, it's actually printing two HTTP requests/responses - because it received two:
GET / HTTP/1.1GET /favicon.ico HTTP/1.1
If you don't see them, your browser may have started caching the response to favicon, and stopped requesting it. You can usually hold the CTRL/Command key while clicking refresh to load it without caching.
It would be great to actually server a graphic, but for now let's just stop lying, and stop returning a 200 response when the favicon.ico is requested. We don't have one, and we should return something cloer to reality - like 404 Not Found.
In order to do this, we need to start differentiating between requests. We have to start actually looking at what the browser is requesting! To do that, we need to parse the HTTP request message instead of just printing it out.
In the code below, we grab the first line of the request message, which contains the verb, path, and HTTP version. We then extract the path by splitting the first line into the three components, and looking at the second part. If the path requested is / we return our HTML. If the path is anything else, we return a 404, since we don't have any other resources on our web server yet.
const on_socket_connect = (socket) => {
socket.on('data', (data) => {
const request = data.toString();
const first_line = request.split('\n')[0];
const path = first_line.split(' ')[1];
if (path === '/') {
const html = `
<!DOCTYPE html>
<html>
<head>
<title>Sample Page</title>
</head>
<body>
<h1>Hello World</h1>
<p>This is fun!</p>
</body>
</html>
`
const response =
'HTTP/1.1 200 OK\n' +
'Content-Type: text/html\n' +
'Content-Length: ' + html.length + '\n' +
'\n' +
html + '\n';
socket.write(response);
}
else {
const text = `404 Sorry not found`;
const response =
'HTTP/1.1 404 Not Found\n' +
'Content-Type: text/html\n' +
'Content-Length: ' + text.length + '\n' +
'\n' +
text + '\n';
socket.write(response);
}
})
}
You can see in web developer tools that the requests to favicon.ico are now showing up as not found. Note, if we type anything in the browser with a different path - like http://localhost:8080/foo/bar, we will get a 404 response back - which is what we want.
We can now start thinking of how we'd server multiple resources. The code below prints a text about message if you visit the http://localhost:8080/about page. I removed some extra whitespace from the HTML to keep things a little more succinct
const on_socket_connect = (socket) => {
socket.on('data', (data) => {
const request = data.toString();
const first_line = request.split('\n')[0];
const path = first_line.split(' ')[1];
if (path === '/') {
const html = `
<!DOCTYPE html><html><head><title>Sample Page</title></head>
<body><h1>Hello World</h1><p>This is fun!</p></body></html>
`
const response =
'HTTP/1.1 200 OK\n' +
'Content-Type: text/html\n' +
'Content-Length: ' + html.length + '\n' +
'\n' +
html + '\n';
socket.write(response);
}
else if (path === '/about') {
const text = `This is just about learning web development.`;
const response =
'HTTP/1.1 200 OK\n' +
'Content-Type: text/plain\n' +
'Content-Length: ' + text.length + '\n' +
'\n' +
text + '\n';
socket.write(response);
}
else {
const text = `404 Sorry not found`;
const response =
'HTTP/1.1 404 Not Found\n' +
'Content-Type: text/html\n' +
'Content-Length: ' + text.length + '\n' +
'\n' +
text + '\n';
socket.write(response);
}
})
}
Improving code through abstractions
To be a web developer is to immediately realize there should be a libary or framework for this... and of course, there is. Take a look closely at the code above. If you were trying to improve it, you might think about (1) creating some utility functions to parse the HTTP request, and (2) creating more utility functions that can be used to generate HTTP responses. Since HTTP is a standard protocol, it makes sense there should be standard functions.
We might imagine something like this, making use of some nice functions
const on_socket_connect = (socket) => {
socket.on('data', (data) => {
const request = parse_http_request(data.toString());
let response = null;
if (request.path === '/') {
const html = `
<!DOCTYPE html>
<html>
<head>
<title>Sample Page</title>
</head>
<body>
<h1>Hello World</h1>
<p>This is fun!</p>
</body>
</html>
`
response = make_http_response(200, 'text/html', html);
}
else if (request.path === '/about') {
response = make_http_response(200, 'text/plain', 'This is just about learning web development.');
}
else {
response = make_http_response(404, 'text/html', 'Sorry not found');
}
socket.write(response.toString());
})
}
The code is a lot clearer, making use of some handy functions to parse HTTP requests and create HTTP responses. Hopefully it is not too hard for you to imagine how these would be written - and more importantly, hopefully it's clear what the advantages are. With these abstractions, we could improve our parsing and response creation a lot more, and be able to reuse this improved parsing and response creation for all our projects. Our parser could parse all the HTTP headers, our response creator could handle many different types of responses, headers, content types.
Of course, these abstractions do exist, in fact multiple level of abstractions exists - from the most basic to the most advanced frameworks used today. We'll start with http, which is built in to Node.js and can replace the use of the net library, but we will eventually (in later chapters) work ourselves all the way up to the Express framework.
The http library
The net library that is built into Node.js has convenient abstractions for creating TCP servers (and clients), sockets, and using sockets to read and write arbitrary data. When writing a web server, we could use the net library, since HTTP is just text data - but we can also opt to use the http library instead.
The http library includes similar features for creating servers (and clients) as the net library, but at a higher level. When creating an http server, TCP is assumed, and sockets are hidden (they still exist, but the library code handles them). Instead of sockets to read from and write to, we receive HTTP request objects and write to HTTP response objects. Request objects are given to our code through callback functions, much like data was given to our function when data was received. The difference is that when data is received on the socket, the http library code is now reading it for us, and parsing it all into a structured object representing the request. The request object has useful properties, like the url being requested and the headers the client sent with the request!
The response object has useful methods, such as writing an initial status line, headers, and content. It makes writing http server far easier, without obscuring what is really happening.
Below is the same web server, with the same functionality, written with the http library instead:
const http = require('http');
const on_request = (req, res) => {
if (req.url == '/') {
const html = `
<!DOCTYPE html><html><head><title>Sample Page</title></head>
<body><h1>Hello World</h1><p>This is fun!</p></body></html>
`
res.writeHead(200, { 'Content-Type': 'text/html' });
res.write(html)
res.end();
}
else if (req.url == '/about') {
const text = `This is just about learning web development.`;
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.write(text)
res.end();
}
else {
res.writeHead(404);
res.end();
return;
}
}
const server = http.createServer(on_request);
server.listen(8080, 'localhost');
That's the entire program, there's no dealing with the net library at all (http uses it however).
No sockets.
When creating the server object, instead of providing a function that will be called when a socket connects, we are providing a function that gets called when an HTTP request is received. The function (on_request) is passed the request object (parsed HTTP request) and a response object. Those objects are then used to serve the response!
Up next
We've now seen the fundamental aspects of the HTTP protocol, and hopefully you have a grasp of how simple it really is - just text/character-based requests and responses. We are going to continue to build our knowledge of HTTP throughout this book, but we will do so within the context of other topics - as needed.
Next, we need to start looking at what HTTP delivers in more detail - and HTTP was primarily made to to deliver is the HyperText Markup Language.
Hypertext Markup Language (HTML) - Part 1

HTML Basics
We've spent the last two chapters really focusing on how data is sent back and forth between the client (a web browser) and server (a web server). These concepts are crucial in your understanding of web development, but they very likely aren't why you became interested in it. Now we turn to looking deeper into how to actually make web pages, which will make up our web applications.
It's worth repeating a bit from Chapter 1, where we examined the relationship between structure, style and interactivity within a web page being displayed by a web browser.
- Structure: HyperText Markup Language (HTML)
- Style: Cascading Style Sheets (CSS)
- Interactivity: JavaScript
HTML is the foundational language we use to describe the structure of a page. It is critical that you separate this from how the page appears. HTML is not the way we arrange the layout of the page, specify colors, alignments, font size, etc. It is simply a way to describe what will be rendered, not necessarily how it will be rendered. Keeping this distinction in mind will pay huge dividends.
HTML is also used to convey semantics of parts of a document. We will have elements like strong, emphasis, paragraphs, lists, tables, articles, navigation and others. They suggest how they might be rendered visually, but they are really about conveying meaning and relationships between parts of text within a document.
There are three core aspects to HTML, or three groups of HTML elements we will learn. The first is content / document structure - like the elements mentioned above. We'll spend the majority of this chapter talking about those. The second is form elements and input controls, where we design input interfaces so users can enter information into our web application. These HTML elements will be covered in Chapter 6, since we'll have to learn a little more about the backend code (Chapter 5) in order to process all this user input. The third group is more subtle - we don't see and interact with them in normal use cases directly. The third group of elements contain metadata and additional resources. These elements describe the document's title, how it might behave on different devices, how it should be interpreted from a security perspective, and what styles and interactivity is embedded and linked to within the document. We'll cover the third group in a variety of places throughout the book, when they each are appropriate.
HTML Versions
There have been a half a dozen or so major versions of HTML, however the only 3 we need to really consider is HTML 4.01, XHTML, and HTML 5 - with the last one being the only version of HTML that anyone develops with in the 2020's. HTML 4.01 is very similar to HTML 5, although it supports fewer element types, and has less sophisticated support for layout, and lacks some of the multimedia and device integration support that HTML5 has defined. Otherwise, it is very much the same language.
The earliest versions of HTML
The original version of HTML was created by Tim Berners-Lee in 1990, as a way of describing hypertext documents. Berners-Lee was working at CERN, the main goal of HTML at this time was to create scientific documents - the design goals were not the same as they are today! An early HTML document would have had elements we continue to use today - and the overall look of the document remains fairly unchanged.
<!DOCTYPE html>
<html>
<head>
<title>This is a title</title>
</head>
<body>
<div>
<p>Hello world!</p>
</div>
</body>
</html>
The initial versions (circa 1992) included title, p, headings, lists, glossary, and address elements. Shortly after, things like img for images and table was added as well. Of course, HTML is only as useful as your ability to render the document as well. At CERN, several worked on creating primitive web browsers. It's important to note that during this time, the language of HTML and the web browsers themselves were evolving together. In many respects, the web browser was the specification of what HTML was - whatever the web browsers expected of HTML, and did with HTML, was HTML.
In 1993, NSCA Mosaic was released, and this is widely considered to be the first browser to have truly wide scale adoption (although the definition of wide scale was very different in the 1990's). In the screenshot below, you should notice some familiar features:
- Address bar (for typing the URL)
- Page title (
title) - Image element (
img) - Hyperlinks (
a) - Horizontal lines (
hr) - Paragraphs (
p)
During most of the 1990's, the vast majority of HTML was written by hand - meaning authors of documents sat down at their computer, opened a text editor, and typed out the contents of HTML. One of the goals of the web was the democratization of technology and communication of information - and thus there was an emphasis on ensuring technical and non-technical people could create content for the web. Browsers allowed for this by being extremely permissive in terms of the syntax of HTML.
As a programmer, you know that these two lines of C++ code aren't the same, even though to a novice the look pretty close:
cout << "Hello World" << endl;
cout << Hello World << endl
The second line won't compile, it's missing quotes around the "Hello World" text, and it's missing it's semicolon. We as software developers get it, you need to write the program using correct syntax. To someone non-technical however, this seems like a drag - and an unnecessary one at that! "It's clear Hello World is what I want to print out, and the end of the line should be good enough - why do I need to write a semicolon!". Honestly, it's a sort of fair point - for a non-programmer.
The early versions of HTML (or, more accurately, browsers) had no problem rendering the following HTML document:
<html>
<head>
<title>This is a title</title>
</head>
<body>
<div>
<p>Hello world!</p>
</body>
</html>
It's missing the DOCTYPE header, and doesn't close the div. No harm no foul. Small inconsistencies and errors in HTML documents resulted in browsers making their best effort to render the page. Remember, the expectations of users were pretty low in the 1990s. If one browser's best effort had a bit different result than another browser's best effort, it wasn't viewed as the end of the world necessarily. Different people coded up the different browsers, and they didn't code up all their attempts to parse valid and invalid HTML the same way. It was understandable!
On the topic of valid/invalid HTML, different browsers also began supporting different subsets of HTML elements. By the middle of the 1990s, the web had begun to move out of scientific and academic venues and straight into consumer's homes. Windows 95 completely revolutionized computing - suddenly millions of people were on the web. Where there are consumers, there is market opportunity, competition for said market, and innovation. Netscape Navigator (a descendent of Mosaic, and ancestor of today's Mozilla Firefox) and Internet Explorer (a step-relative so to speak of today Edge browser) competed for users. One of the ways these browsers competed (beyond how well they dealt with HTML errors in people's documents) was by inventing new elements.
All sorts of elements began to crop up - font, texttop, center, big, small, blink, marquee, applet and many many more. Some were supported first by Internet Explorer, some were created by Netscape. Some were quickly adopted by the other, to remain on par. Some were answered with different and competing elements. This quickly began to spiral however, as web authors now needed to adhere to different HTML rules for different browsers - which was essentially impossible to do well! We began to see things like "This site is best viewed with Microsoft Internet Explorer" written along the top of website, indicating to the user that the site might be using elements that Netscape didn't support.
Non-compatibility, ambiguous rules, and competing features sets threatened the future of the web.
Things were not well in the late 1990's.
XML and XHTML
XHTML is a bit of a misunderstood variant of HTML itself. Before describing it, let's define the elephant in the room when it comes to HTML and XHTML - and that's XML. The eXtensible Markup Language is a markup language (and often a file format) used to store structured data. It was defined by the World Wide Web Consortium in 1998, and was (and still is) a huge player in the structure data space (it has been supplanted by the more simple JSON format in many areas within the last 10-15 years however). XML, if you haven't seen it before, is a pretty familiar looking thing - at least on the surface:
<?xml version="1.0" encoding="UTF-8"?>
<library>
<book>
<title>The Great Gatsby</title>
<author>F. Scott Fitzgerald</author>
<year>1925</year>
<genre>Fiction</genre>
<price>10.99</price>
<isbn>9780743273565</isbn>
<publisher>Scribner</publisher>
</book>
<book>
<title>1984</title>
<author>George Orwell</author>
<year>1949</year>
<genre>Dystopian</genre>
<price>9.99</price>
<isbn>9780451524935</isbn>
<publisher>Houghton Mifflin Harcourt</publisher>
</book>
<book>
<title>To Kill a Mockingbird</title>
<author>Harper Lee</author>
<year>1960</year>
<genre>Fiction</genre>
<price>7.99</price>
<isbn>9780061120084</isbn>
<publisher>J.B. Lippincott & Co.</publisher>
</book>
<book>
<title>The Hobbit</title>
<author>J.R.R. Tolkien</author>
<year>1937</year>
<genre>Fantasy</genre>
<price>8.99</price>
<isbn>9780547928227</isbn>
<publisher>George Allen & Unwin</publisher>
</book>
</library>
As you can see, the XML document above describes a library of books. XML arranges hierarchies of "objects" or entities, in a human readable format. The language can become quite complex however - particular when considering defining an XML document's schema. The concept of schema is that documents have a pre-defined structure. Imagine having many XML files, each describing collections of books - the schema is the agreement between all authors of such documents on such details as (1) the root element is called library, the year of publication is called year rather than something like publication-year, for example. The schema describes the rules of the XML document. The XML schema sub-language is really what made XML extensible, anyone could describe a set of rules, using XML schema language, and thus (at least, in theory) and program could produce and consume those XML documents.
You may be wondering, with some basic knowledge of HTML, whether HTML is XML - since from what we just described, it seems perfectly logical that HTML could be defined using an XML schema! HTML is just a set of specific XML elements for creating HTML documents. Your intuition is somewhat correct - however HTML pre-dates XML. As mentioned above, the original version of HTML was developed by Tim Berners-Lee almost 10 years prior. The language looks like XML, but it wasn't general purpose. In reality, XML was a generalization of the already popular HTML language!
XML was developed to solve some of the problems of the initial version of HTML, in the data exchange space. While HTML had many quirks, and was very permissive in terms of syntax, when exchanging arbitrary data between programs those ambiguities are a bug, not a feature. XML is more restrictive than early versions of HTML - for example, the document is entirely invalid if you do not <close> an element with a corresponding </close> tag, or forget to include quotes enclosing an attribute. XML of course introduced the secondary XML schema language as well.
Once XML was developed, it was a pretty obvious next step to develop a new HTML standard described as an XML schema. Thus, the Extensible HyperText Markup Language (XHTML) was born (2000). XHTML was simply the HTML language, adapted such that it was a conformant XML document, with a well defined XML schema outlining the language rules (rather than the rules being decided by a collaboration of standards bodies authoring text descriptions, and browsers actually implementing rendering of said HTML). In the early 2000's XHTML appeared poised to become the dominant form of HTML - there was a huge amount of support behind XML in nearly all areas of Computer Science and Software Engineering.
The story didn't actually go as planned for XHTML however. While from a strictly engineering standpoint, having a rigorous and unambiguous specification (using XML Schema) of the language was a gigantic leap forward - that strictness was also a liability. Remember, in the early 2000's a lot of HTML was still being written by novices, by hand (not generated by programs). XHTML did not offer any feature enhancements over standard HTML in terms of things that developers could do that their users could see. Yes, XHTML was a better technology - since XHTML was harder to write, and didn't offer any user-facing benefits, it just didn't gain the level of traction we thought it would.
Browser Wars
While XHTML aimed to achieve rigor, it was not widely adopted by authors. Thus, in the mid 1990's, web authors were stuck dealing with some rather significant inconsistencies between what dialect of HTML different browsers supported. We don't need to get into the details here, but you should also note that the differences were even more magnified when it came to how styling with CSS and interactivity with JavaScript was supported across browsers. Until the late 1990's and early 2000's, the main browsers were Netscape and Internet Explorer. Given their share of the market, there were efforts to somehow standardize the HTML language to avoid having two completely distinct dialects of HTML evolving in the wild. To large effect, this was achieved with the ratification by the World Wide Web Consortium of HTML 4.0 (and HTML 4.01) in late 1990's - however, as you can see in the image below, by that time Internet Explorer had effectively become the standard. It had won the Browser war. While Microsoft Internet Explorer largely adopted HTML 4.01 (the standard was based in part on what Internet Explorer supported in the first place!), it did continue to support other features.

Image linked from Wikipedia
.png){kind=link}
Towards the right of the image above, you see another competitor enter the scene - Google Chrome. In 2009, it's usage was small - however it marked a very important turning point in web browsers. Google Chrome of course supported HTML 4.01, however it also had an important killer feature - JavaScript performance. At the time of it's release, JavaScript (which is only loosely defined by the HTML specification) was a backwater in web development. Different browsers supported it differently, and performance was pretty abysmal. Google Chrome changed the architecture (more on this later in the book), and achieved performance increases in JavaScript execution by several orders of magnitude.
In 2007, another important development took place that ultimately changed HTML, CSS, and JavaScript as well - the first iPhone was released. At the time, the web was split along a second axis - interactivity. As described above, JavaScript was a poor alternative for creating the types of richly interactive web applications we expect today. Web applications that served mainly documents used HTML, CSS, and some JavaScript, but web applications that served up interactive visualizations, games, maps, etc used a completely different language (embedded within HTML) - Adobe Flash. You can learn more about Flash on the web, and it's an important part of the evolution of the web - but the reason it's brought up here is that the iPhone not only didn't support it, but Apple unambiguously stated it would never support it. It was incredibly controversial, yet proved pivotal. The iPhone had two characteristics which made it uniquely positioned to drive change - (1) it was a wild success, and (2) it's form factor (mobile!) offered lots of new ways to envision how web applications could interact with the device and the user. By refusing the adopt Adobe Flash, and instead pointing towards the promise of JavaScript (just starting to take shape in early version of Google Chrome), Apple effectively put a giant thumb on the scale - leading to the complete demise of Flash, and more importantly - an incredible thirst in the market place for better JavaScript.

Image linked from Wikipedia
In the graphic above, you can see how Google Chrome (desktop and Android devices) and Apple Safari (the iPhone's browser, along with Mac) completely destroyed Internet Explorer's dominance among browsers. During the 2000s and 2010s, we returned to a time where there was not one dominant browser - and this was an opportunity. Without a dominant browser, all browser vendors benefit from strong standards - learning the lessons of the 1990's browser wars. With an opportunity for stronger standardization, and a serious need for a new set of standards to better support the new web - multimedia, multi-device, and enhanced capabilities - the World Wide Web Consortium's HTML 5 specification (which was being developed in parallel to all of these new developments) was right in time.
HTML 5 and beyond
The development of HTML 5 began with the first public working draft in early 2008. Public releases of draft standards continued through the early 2010's, with browsers often adopting parts of the draft standards that appeared stable. The first formally released standard came in October 2014. HTML 5 was a major milestone in web development, aimed at modernizing how the web is built and experienced. The goal was to address the limitations of earlier versions of HTML, while reflecting the evolving needs of web developers and users. With the rise of multimedia, dynamic content, mobile browsing, and web applications, HTML5 provided much-needed improvements in functionality, performance, and standardization.
One of the key drivers behind HTML5’s development was the need to natively support richer multimedia and interactivity directly in the browser. Before HTML5, embedding video or audio required third-party plugins such as Adobe Flash or Microsoft SilverLight, which were power hungry, slow, and insecure. HTML5 introduced native <video> and <audio> elements, making it easier to embed media content without relying on external technologies. This change empowered browsers to handle media more efficiently and securely, contributing to a more seamless web experience, especially on mobile devices, where performance is critical.
Another major feature of HTML5 was the introduction of new semantic elements like <header>, <footer>, <article>, <section>, and <nav>. These elements added meaning to the structure of web pages, enabling developers to better organize content and improving accessibility for assistive technologies like screen readers. Semantic HTML not only enhances the user experience but also helps search engines better understand the content on a page, improving SEO and making the web more intuitive for machines and users alike.
HTML5 also worked hand-in-hand with JavaScript, empowering developers to build more powerful and interactive web applications. New APIs like the Canvas API for drawing graphics, Geolocation API for location-based services, and Web Storage API for local data storage enabled richer experiences without the need for external libraries or plugins. This shift allowed developers to create applications that previously would have required native desktop software, ushering in a new era of web applications.
Standardization was another critical goal. HTML5 sought to unify the web development landscape, where browser-specific code and fragmented implementations had long been an issue. By setting clear rules and specifications, HTML5 helped ensure that all major browsers (Chrome, Firefox, Safari, Edge, etc.) would render content consistently, reducing the need for browser-specific hacks and workarounds. This emphasis on standardization paved the way for smoother cross-browser development and a more reliable user experience across devices and platforms.
In short, HTML5 was necessary because it aligned the language of the web with modern requirements, streamlining multimedia, enhancing semantics, improving JavaScript capabilities, and unifying the development process. These features laid the foundation for a more efficient, accessible, and future-proof web.
In the rest of this chapter, we will exclusively target HTML 5. While incremental version of HTML 5 continue to be released, the changes have been limited. When we cover CSS and JavaScript, we likewise will target the capabilities of modern browsers supporting HTML 5 fully - as HTML 5 is sort of an umbrella for not only modern HTML, but also modern CSS and JavaScript.
HTML History
This section covered HTML history at a really, really high level. The intent is to give you a bit of a glimpse as to how we got where we are today. The history of web browsers and HTML is a fascinating one however, and you are really encouraged to learn more about it! Mozilla has a nice front-page, here that has several links to other resources - it's a great start.
HTML Structure
As the last section describes, HTML has a very long and winding history. You may have heard the saying that "nothing is ever gone from the internet", or something to that effect. Bad (or just old) HTML never leaves the internet either. If you surf the web long enough, you are going to see all sorts of HTML pages - some using upper case elements intead of lower case elements (or a mix of both), some using deprecated elements, and other "quirks". The terms "quirks" is actual an official term - most browsers will have "quirks" mode, which cases the HTML to rendered not be the modern HTML 5 parsing engine (the newer, and undoubtedly better code) in the browser, but instead by older code.
As a modern web developer, you must develop a strong sense of embarrassment about writing poor HTML. As a web developer, you have a professional responsibility to write standards compliant HTML 5. This allows you to reap the rewards of all of the (phenomenal) advancements browsers have made over the past decade. There is no excuse. An ability to understand how to write HTML correctly will prevent you from ever getting a serious job in web development.
Structure of a Standard HTML Document
The structure of the document starts with the very first line - the doctype line. This line communicates, in the first bytes of the response body that the browser reads from it's TCP socket, what kind of HTML document is receiving. As such, this line will be processed before the parser is loaded. Choose the correct doctype, your page will be processed with the browser's modern parser and render. Choose poorly (or not at all), and you are thrown into the badlands of the early 2000's - and it's not fun.
The correct doctype is fortunately easy - it's simple html. THe first element - <!DOCTYPE html> is not like all the rest - it has an ! character, and it is capitalized. Technically, this is case sensitive, although you will often see <!doctype html> written in HTML-like files that will be processed / transformed into standard HTML (more on this later in the book).
<!DOCTYPE html>
<html>
<head>
<title>This is a title</title>
</head>
<body>
<div>
<p>Hello world!</p>
</div>
</body>
</html>
The remaining part of the HTML document above is just that - HTML markup. HTML (and XML) is a tree-styled document, where elements enclose other elements - beginning at the root of the document. The root of all HTML documents is the html element. An element is defined as the entire HTML "element" - the opening tag (<html>), the content (the child elements), and the closing tag (